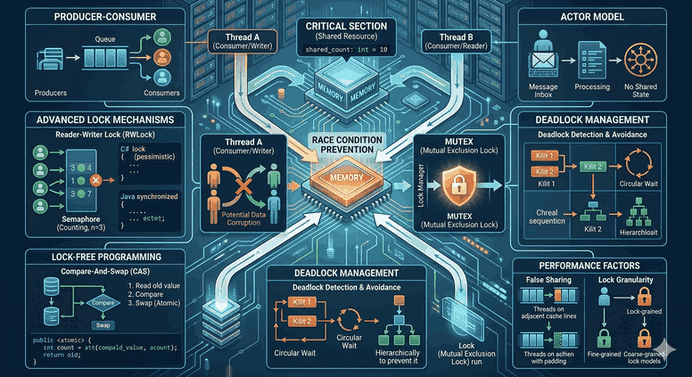
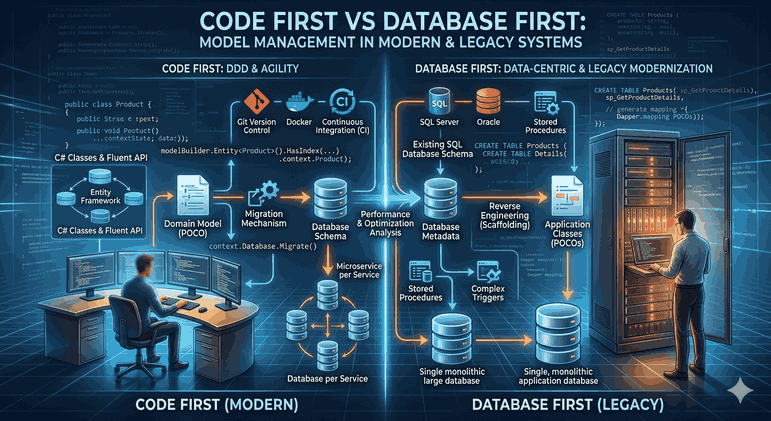
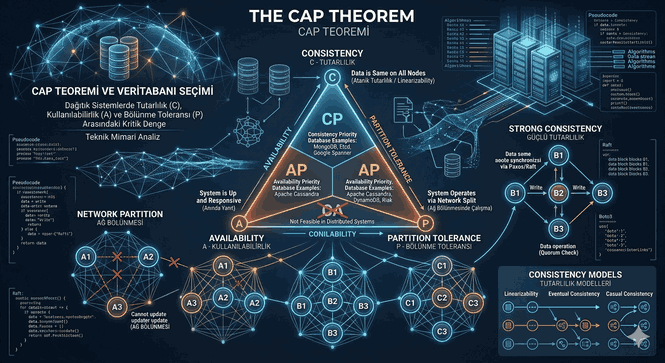
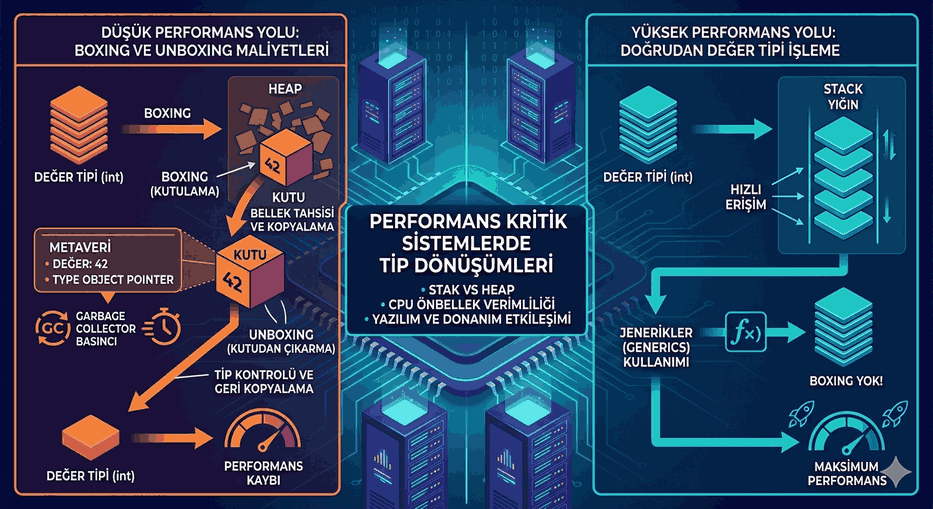
We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
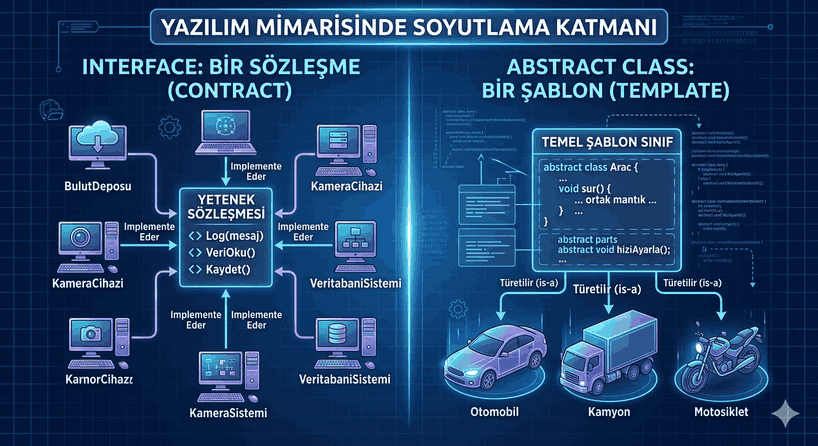
Dependency Inversion and Abstraction Layer: Breaking Tight Coupling Between Layers
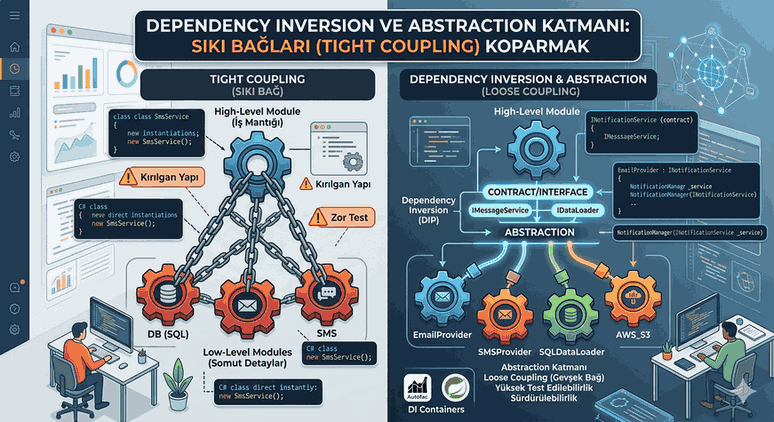
Sustainability and flexibility in software architecture are directly related to how “independent” the components of the code are. The biggest problem encountered in modern software development processes is that a change made in lower-level modules causes the upper-level business logic to break due to a domino effect. This situation is referred to in software literature as the Tight Coupling Problematic.
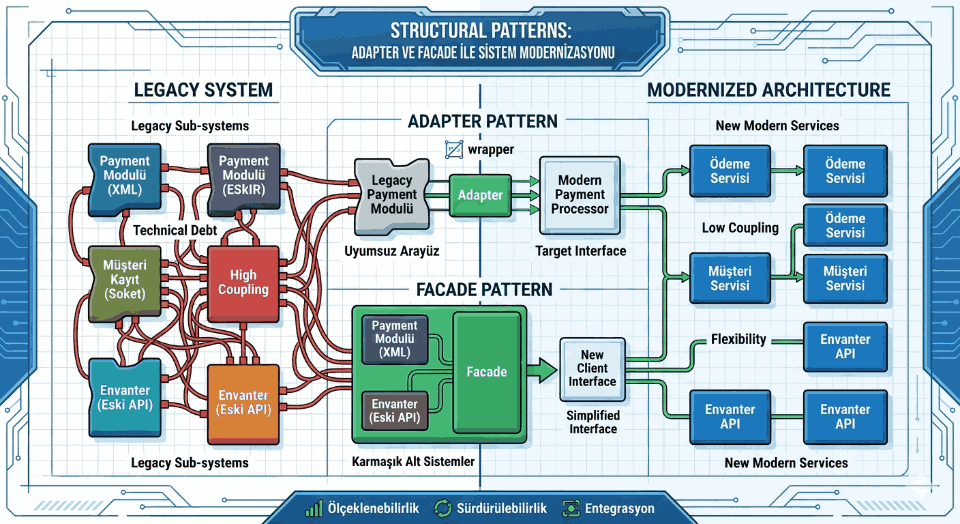
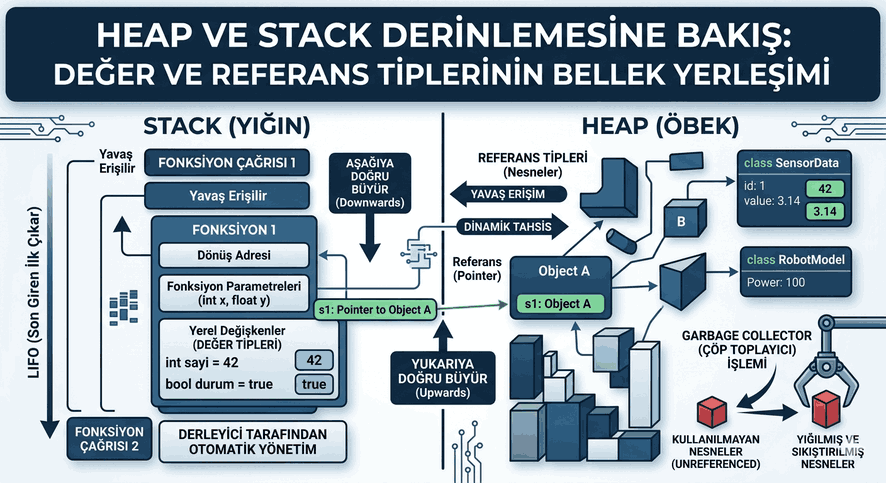
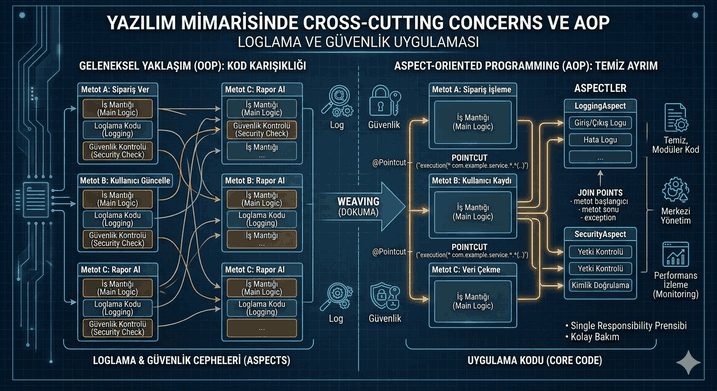
Figure 1: Dependency Inversion and Abstraction Layer: Breaking Tight Coupling Between Layers
1. Tight Coupling: Architectural Shackles
Tight coupling occurs when a class or module directly depends on another concrete class to function. Technically, the fundamental basis for this dependency is when a high-level component directly instantiates a low-level component using the new keyword.
Technical Risks of Tight Coupling:
Loss of Testability: It becomes impossible to “mock” the dependent class in Unit Tests.
Rigidity: A change in one module ripples throughout the system.
Fragility: Runtime errors occur in seemingly unrelated areas.
2. Dependency Inversion Principle (DIP) Analysis
DIP turns the traditional software design dependency hierarchy upside down. The principle is based on two fundamental points:
High-level modules should not depend on low-level modules. Both should depend on abstractions (interfaces/abstract classes).
Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
The critical distinction here is that an “Abstraction” acts as a contract. The high-level module knows “what to do” but is not concerned with “how it is done.”
3. Abstraction Layer: Strategic Bridge
The abstraction layer is a barrier placed between the unchanging parts of the system and the constantly changing (detail) parts. Database technologies, file systems, third-party APIs, and UI components are “details.” Business logic, however, is the “essence.”
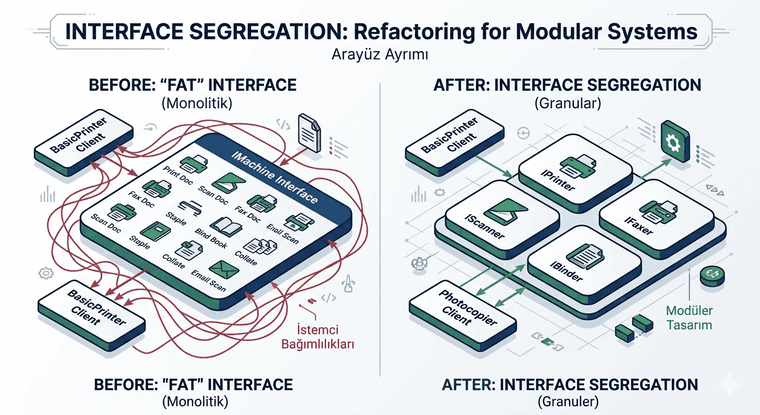
3.1. Relationship with Interface Segregation
When creating an abstraction layer, massive interfaces that do everything should be avoided. Instead, small interfaces focusing on specific tasks should be defined. This prevents the client from depending on methods it does not use.
4. Technical Implementation and Code Architecture Example
Let’s consider the notification structure in an e-commerce system. In the traditional method, the order class is directly tied to an SMS service; when DIP is applied, the system takes on a completely abstract structure.
4.1. Bad Design (Tight Coupling)
publicclassSmsService {
publicvoid SendSms(string message) { /* Send SMS */ }
}
publicclassOrderManager {
privatereadonly SmsService _smsService = new SmsService(); // Tight Coupling!publicvoid CompleteOrder() {
// Business logic... _smsService.SendSms("Your order has been received.");
}
}
4.2. Good Design (DIP and Abstraction)
Here, we reverse the dependency by defining an IMessageService interface (abstraction).
5. Dependency Injection (DI) Containers and Libraries
Managing abstraction layers manually is difficult in complex systems. This is where Inversion of Control (IoC) containers come into play. These tools automate object lifecycles and dependency resolutions.
publicvoid ConfigureServices(IServiceCollection services) {
// When IMessageService is requested at runtime, EmailProvider will be provided. services.AddScoped<IMessageService, EmailProvider>();
// Changing it is as simple as this:// services.AddScoped<IMessageService, WhatsappProvider>();}
6. DIP in the Context of MLOps and Data Science
DIP is critical not only in web or desktop software but also in modern Data Pipelines. For example, in a model training process, the data source (SQL, NoSQL, S3 Bucket) should be hidden behind an abstraction.
Data Access Abstraction Example (Pythonic Abstraction):
from abc import ABC, abstractmethod
classIDataLoader(ABC):
@abstractmethoddefload_data(self):
passclassS3DataLoader(IDataLoader):
defload_data(self):
# Logic for fetching data via AWS S3return"S3 Data"classSQLDataLoader(IDataLoader):
defload_data(self):
# Logic for fetching data via PostgreSQLreturn"SQL Data"classModelTrainer:
def__init__(self, loader: IDataLoader):
self.loader = loader
deftrain(self):
data = self.loader.load_data()
print(f"Training model using {data}...")
7. Performance and Architectural Cost Analysis
Adding abstraction layers introduces a certain amount of “indirection” to the system. However, this cost is negligible compared to the flexibility provided.
V-Table Lookups: The use of virtual functions in languages like C++ creates a very small overhead.
Memory Footprint: While IoC containers optimize memory management, incorrectly configured “Singleton” or “Transient” lifecycles can lead to memory leaks.
Important Note: Be wary of the “over-engineering” trap. If it is certain that a component will never change throughout its lifetime and no other variation will exist, adding an abstraction layer can create unnecessary complexity.
The following criteria should be considered for an effective abstraction layer:
Avoid Leaky Abstractions: The abstraction should not propagate details of the low-level technology (e.g., SQL error codes) to the high-level.
Minimum Interface: Only necessary methods should be defined.
Exception Handling: Error management should be standardized at the abstraction level. If a low-level library throws a specific error, this error should be converted to a general error type understood by the high level.
Conclusion
Dependency Inversion and abstraction layers are the most powerful shields preventing software from being crushed under “Technical Debt.” Avoiding monolithic approaches where code is tightly coupled and building an ecosystem where modules talk only through contracts is the key to scalable and evolvable systems. It should not be forgotten that a good architecture is one where decisions (such as database selection or message queue service) can be postponed as long as possible. Abstraction provides the developer with this power of postponement.