We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
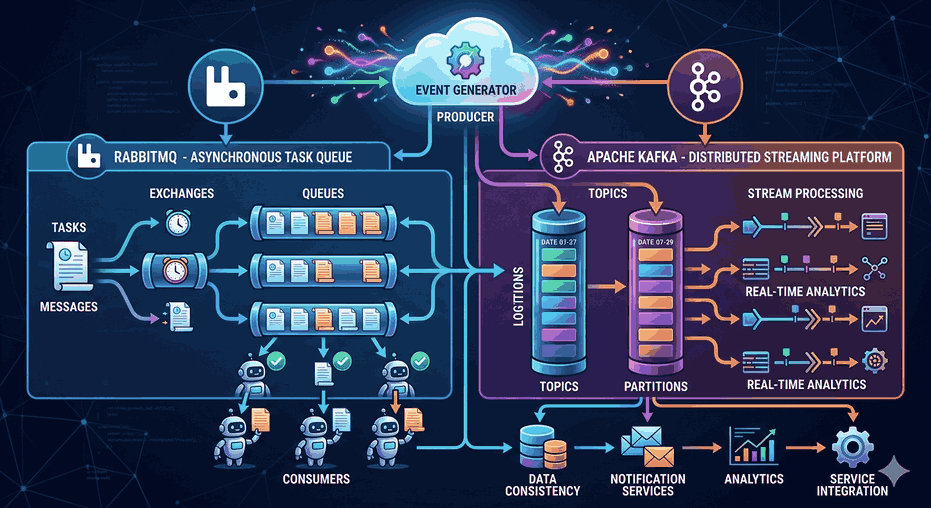
Data Consistency and Distributed System Paradigms in Modern Database Architectures
In today’s high-scale software architectures, database selection and design is the most critical decision directly impacting system uptime, data integrity, and end-to-end performance. For a software architect, a database is not just a disk space where data is stored; it is a delicate balance mechanism established between mathematical theories, network constraints, and hardware limitations.
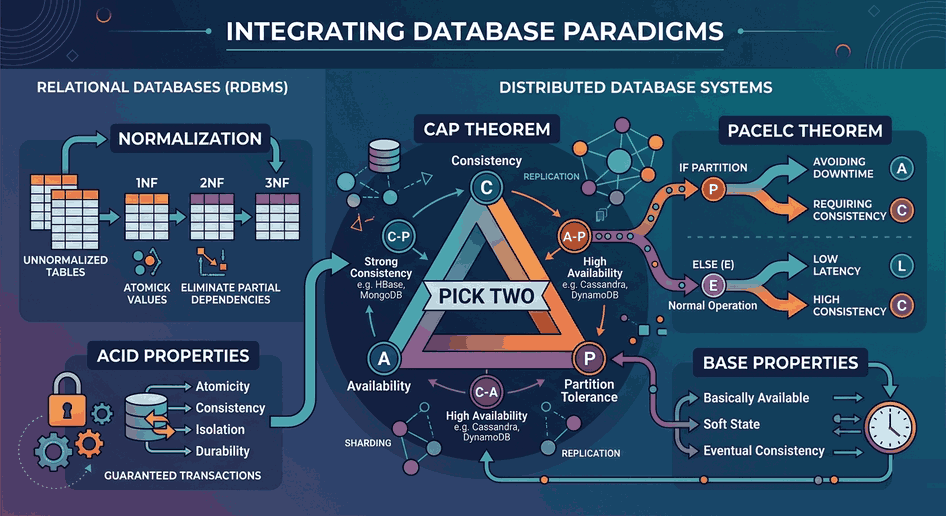
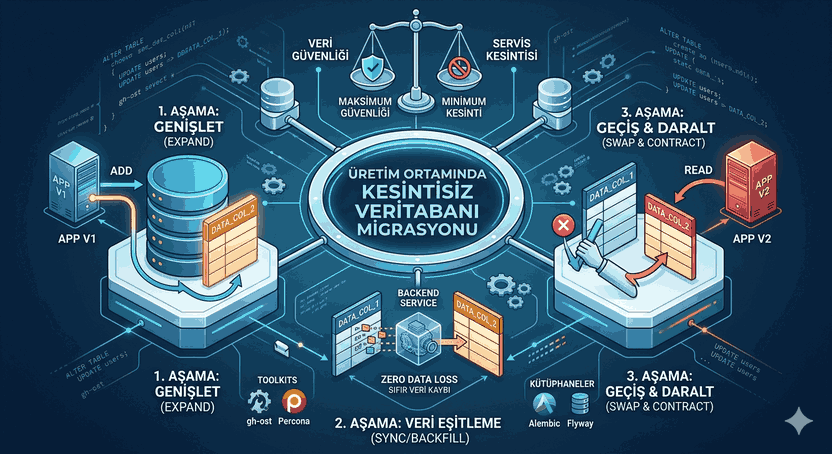
Figure 1: Data Consistency and Distributed System Paradigms in Modern Database Architectures.
1. Mathematical Foundation of Data Modeling: Relational Design and Normalization
At the core of relational databases (RDBMS) lie the relational model and set theory developed by Edgar F. Codd. Normalization forms are utilized to prevent data anomalies, minimize data redundancy, and ensure storage optimization.
Technical Analysis of Normal Forms
1NF (First Normal Form): Each column must contain atomic (indivisible) values. A single cell cannot contain comma-separated lists or repeating groups.
2NF (Second Normal Form): The system must be in 1NF and must not contain partial dependencies. That is, all columns that are not part of a composite primary key must be fully dependent on the entire key.
3NF (Third Normal Form): The system must be in 2NF and must not contain transitive dependencies. A non-primary key column cannot depend on another non-primary key column (preventing the scenario where if $A \rightarrow B$ and $B \rightarrow C$, then $A \rightarrow C$).
BCNF (Boyce-Codd Normal Form): A stricter version of 3NF. Every determinant must be a candidate key.
Normalization and Index Optimization on PostgreSQL
The following SQL script creates an e-commerce schema adhering to 3NF standards and utilizes the B-Tree indexing mechanism to reduce query costs.
-- We normalize address information to prevent redundancy (3NF)
CREATETABLE cities (
city_id SERIAL PRIMARYKEY,
city_name VARCHAR(100) NOTNULLUNIQUE);
CREATETABLE users (
user_id SERIAL PRIMARYKEY,
email VARCHAR(255) NOTNULLUNIQUE,
created_at TIMESTAMPWITH TIME ZONEDEFAULTCURRENT_TIMESTAMP);
-- We break transitive dependencies in the orders table
CREATETABLE orders (
order_id UUID PRIMARYKEYDEFAULT gen_random_uuid(),
user_id INT NOTNULL,
order_date TIMESTAMPWITH TIME ZONENOTNULL,
total_amount NUMERIC(12, 2) NOTNULL,
CONSTRAINT fk_user FOREIGNKEY (user_id) REFERENCES users(user_id) ONDELETERESTRICT);
-- We define a B-Tree index to improve search performance
CREATEINDEX idx_orders_user_date ON orders(user_id, order_date DESC);
Architectural Note: As the normalization level increases, data consistency reaches its maximum, but a drop in read performance may occur because table joins (JOINs) will increase. In such cases, Denormalization techniques are intentionally applied in analytical systems (OLAP).
2. Reliability Guarantee in Monolithic Systems: ACID Principles
In traditional databases running on a single server, data integrity is protected by four core principles known as ACID.
Atomicity: All SQL commands within the scope of a transaction must either succeed completely, or the system must revert to its state before the transaction started (rollback) even in the case of a single error.
Consistency: The database must maintain all defined rules (constraints, foreign keys, triggers) before and after the transaction. Data cannot fall into an invalid state.
Isolation: Multiple transactions executing concurrently must not see each other’s intermediate states. Isolation levels (Read Uncommitted, Read Committed, Repeatable Read, Serializable) determine the trade-off between performance and consistency.
Durability: Once a transaction is successfully completed (commit), the data is permanently stored on the disk, even in the event of a power outage or system crash. This is typically achieved via the WAL (Write-Ahead Logging) mechanism.
ACID Transaction Management with C# / Entity Framework Core
In the code block below, a funds transfer between two different accounts is simulated. By utilizing an advanced isolation level (Serializable), race conditions such as “Phantom Read” and “Non-repeatable Read” are prevented.
using Microsoft.EntityFrameworkCore;
using System;
using System.Transactions;
publicclassBankContext : DbContext
{
public DbSet<Account> Accounts { get; set; }
protectedoverridevoid OnConfiguring(DbContextOptionsBuilder options)
=> options.UseNpgsql("Host=localhost;Database=BankDb;Username=postgres;Password=secret");
}
publicclassAccount{
publicint AccountId { get; set; }
publicdecimal Balance { get; set; }
}
publicclassWalletService{
privatereadonly BankContext _context;
public WalletService(BankContext context)
{
_context = context;
}
publicbool TransferFunds(int sourceId, int targetId, decimal amount)
{
// Initiating the transaction at the highest isolation levelusing var transaction = _context.Database.BeginTransaction(System.Data.IsolationLevel.Serializable);
try {
var sourceAcc = _context.Accounts.Find(sourceId);
if (sourceAcc == null || sourceAcc.Balance < amount) thrownew InvalidOperationException("Inadequate funds.");
var targetAcc = _context.Accounts.Find(targetId);
if (targetAcc == null) thrownew InvalidOperationException("Target account not found.");
// Balances are being updated sourceAcc.Balance -= amount;
targetAcc.Balance += amount;
_context.SaveChanges();
// If all operations are successful, it is written to disk (Atomicity & Durability) transaction.Commit();
returntrue;
}
catch (Exception)
{
// At the slightest error, the system reverts to its previous state transaction.Rollback();
returnfalse;
}
}
}
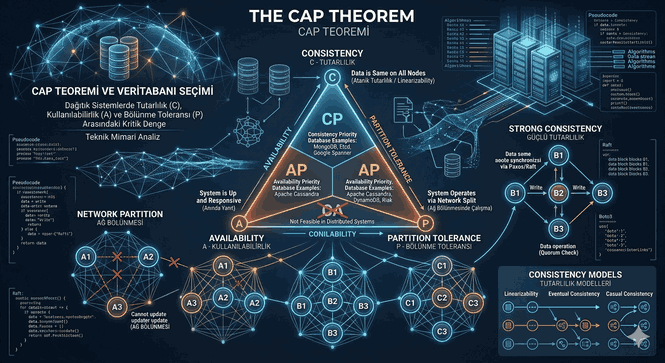
3. The Inevitable Reality of Distributed Systems: The CAP Theorem
When a system scales and exceeds the limits of a single server, data is copied across multiple nodes (replication). The CAP Theorem, formulated by Eric Brewer, proves that a distributed system can only fully provide two of the following three properties at the same time:
Consistency: Every node reads the most recent data at the same time. Data written to one node is instantly updated across all other nodes.
Availability: Even if some nodes in the system crash, every working node must be able to return a response (read/write) without throwing an error.
Partition Tolerance: The system must continue to operate when network communication between nodes breaks down or packets are lost (network partition).
Since disruptions and latencies are inevitable in real-world networks, a distributed system must architecturally choose Partition Tolerance (P). In this case, the choice is reduced to two options:
CP (Consistency / Partition Tolerance): To maintain consistency when the network partitions, availability is sacrificed. If synchronization between nodes cannot be achieved, an error is returned (e.g., HBase, MongoDB, Redis).
AP (Availability / Partition Tolerance): When the network partitions, the system continues to respond under all conditions, but different (stale) data may be read from different nodes. When the network recovers, the data is synchronized (e.g., Cassandra, CouchDB).
4. What Happens When There Is No Network Partition? The PACELC Theorem
Because the CAP Theorem focuses solely on the event of a network partition (Partition), it ignores latency parameters under normal operating conditions. The PACELC Theorem, developed by Daniel Abadi, fills this gap left by CAP.
The formulation reads as follows: If there is a network partition (P), the system chooses between Availability or Consistency; Else (otherwise, meaning when the system is operating normally), the system must choose between Latency or Consistency.
This theorem divides databases into four main classes:
Class
During Partition
During Normal Operation
Example Database
PC/EC
Consistency (C)
Consistency (C)
PostgreSQL (Sync Repl.), BigTable
PA/EL
Availability (A)
Low Latency (L)
Apache Cassandra, Amazon DynamoDB
PC/EL
Consistency (C)
Low Latency (L)
MongoDB (Primary-Secondary)
PA/EC
Availability (A)
Consistency (C)
VoltDB
5. The Flexible Approach of the Distributed World: The BASE Model
The rigid consistency rules of the traditional ACID model cause performance bottlenecks in horizontally scaling AP/EL class distributed systems. To overcome this bottleneck, the BASE model was developed:
Basically Available: The system guarantees a response to every query, even if data consistency is compromised. Partial outages do not stop the system entirely.
Soft State: Data states are dynamic. Because synchronization between nodes continues in the background, data can change over time even without external input.
Eventual Consistency: The system may temporarily present inconsistent data, but after a certain period, if no new updates arrive, all nodes synchronize and display the same data.
Eventual Consistency Settings with Node.js and DataStax Cassandra Driver
Apache Cassandra is one of the most aggressive implementers of the PA/EL model in PACELC theory. Architectural flexibility can be achieved by configuring consistency levels on a per-query basis.
constcassandra=require('cassandra-driver');
// Cluster connection settings
constclient=newcassandra.Client({
contactPoints: ['192.168.1.50', '192.168.1.51'],
localDataCenter:'datacenter1',
keyspace:'inventory'});
asyncfunctioninsertProductStock(productId, stockCount) {
constquery='UPDATE product_stock SET stock = ? WHERE product_id = ?';
// Managing the PACELC balance at the code level
// LOCAL_QUORUM: Waits for confirmation from the majority of nodes (High Consistency - EC balance)
// ONE: Writing to a single node is sufficient (Low Latency - EL balance)
constoptions= {
prepare:true,
consistency:cassandra.types.consistencies.localQuorum };
try {
awaitclient.execute(query, [stockCount, productId], options);
console.log('Stock updated successfully under Quorum consensus.');
} catch (err) {
console.error('Consensus failed or network timed out:', err);
}
}
asyncfunctiongetProductStock(productId) {
constquery='SELECT stock FROM product_stock WHERE product_id = ?';
// We set the eventual consistency level to 'ONE' to reduce latency in read operations
constoptions= {
prepare:true,
consistency:cassandra.types.consistencies.one };
constresult=awaitclient.execute(query, [productId], options);
returnresult.rows[0];
}
6. Advanced Consensus Algorithms and Distributed Isolation
Modern NewSQL databases (CockroachDB, Google Spanner) aim to combine the vertical reliability of ACID with the horizontal scalability of NoSQL. These systems use consensus algorithms such as Raft or Paxos to securely distribute data among nodes and approve mutations.
Additionally, since the perception of time and clock synchronization is difficult in distributed systems (due to NTP drifts), globally unique ordering mechanisms (TrueTime API or Hybrid Logical Clocks - HLC) come into play. In this way, the Serializable isolation level can be achieved even across geographically distributed nodes.
Conclusion and Architectural Selection Matrix
Choosing the right database architecture depends on the business logic requirements of the application. In projects that require financial transactions, accounting, and absolute data accuracy, ACID-compliant, normalized RDBMS structures should be preferred. In social media platforms, IoT telemetry systems, or big data analysis tools where real-time data flow is high and milliseconds are critical, NoSQL architectures designed with a PA/EL focus in the PACELC matrix, embracing the BASE model, will guarantee operational continuity.