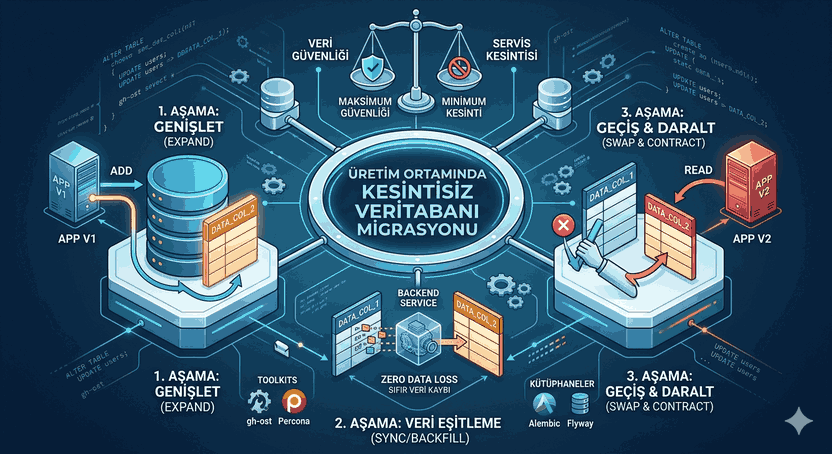
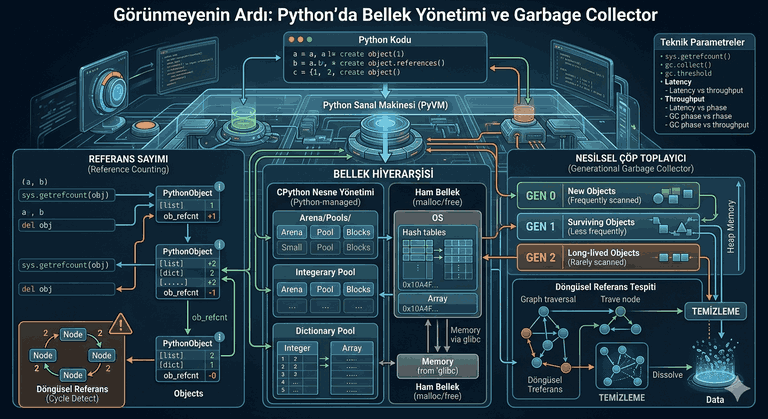
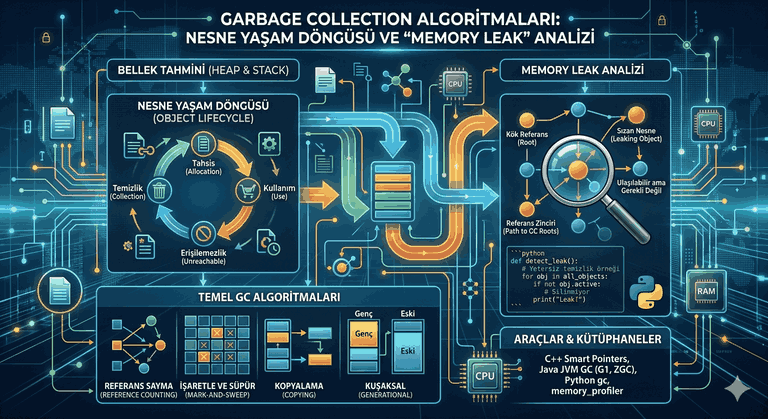
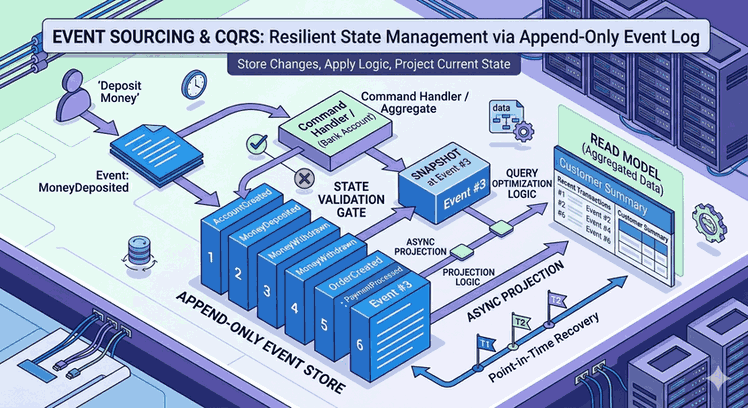
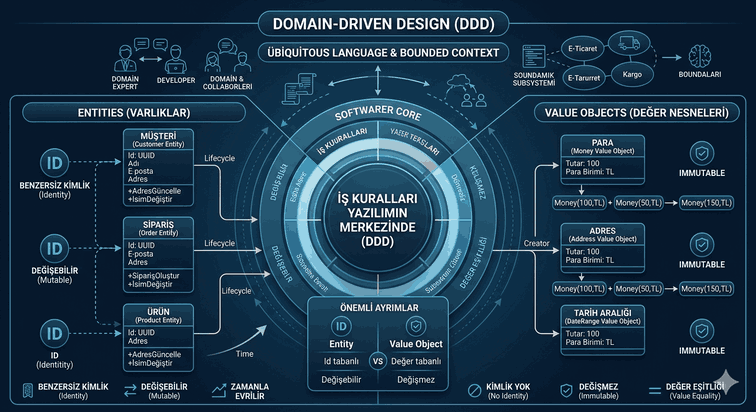
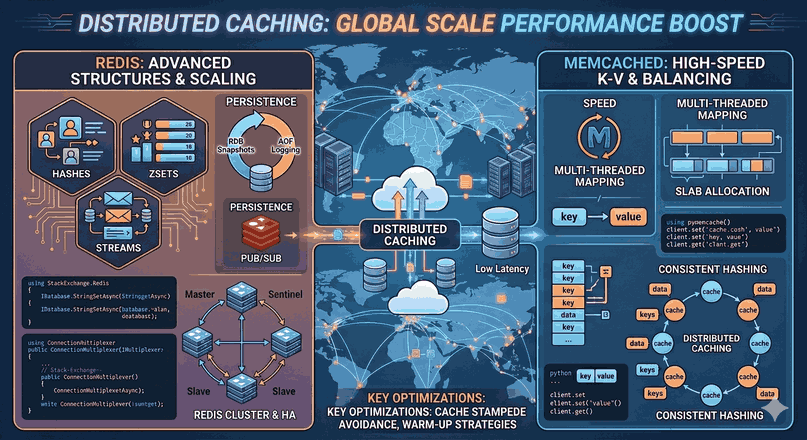
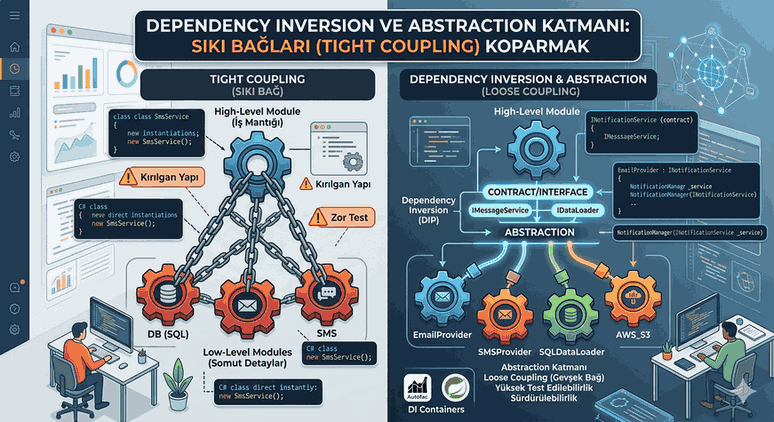
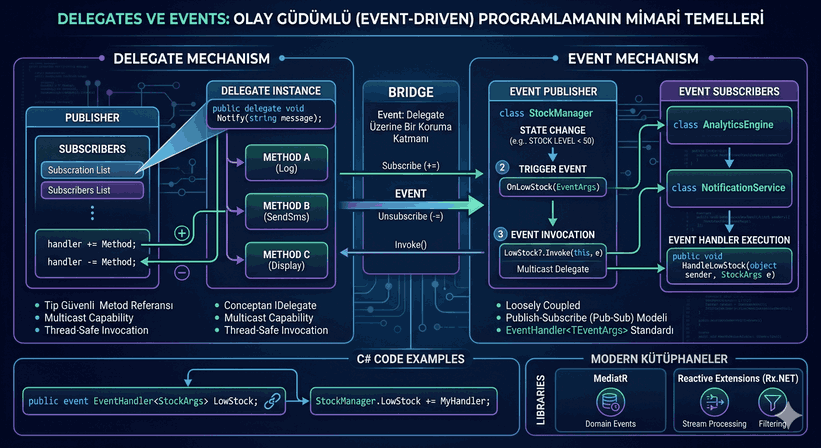
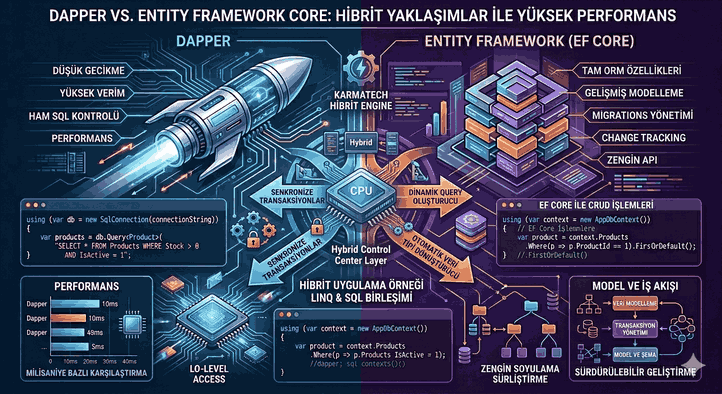
We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
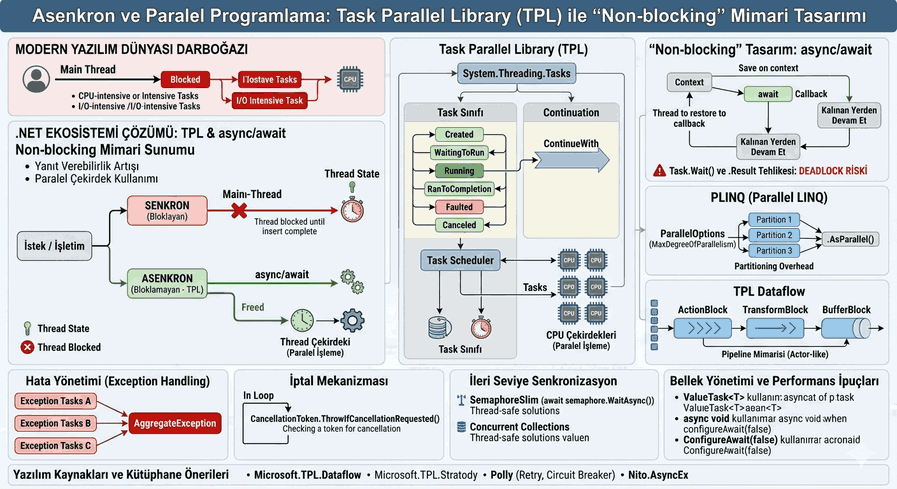
Autonomous Systems and AI Integration: Using LLMs as an Architectural Layer and Code Analysis
The evolution of autonomous systems is shifting from classical control theories and deterministic algorithms towards dynamic structures with cognitive capabilities. Traditional robotics and autonomous systems were limited by predefined decision trees and sensor fusion algorithms. However, the integration of Large Language Models (LLMs) as a systematic “architectural layer” has fundamentally changed the uncertainty management and complex task planning capacity of these systems.
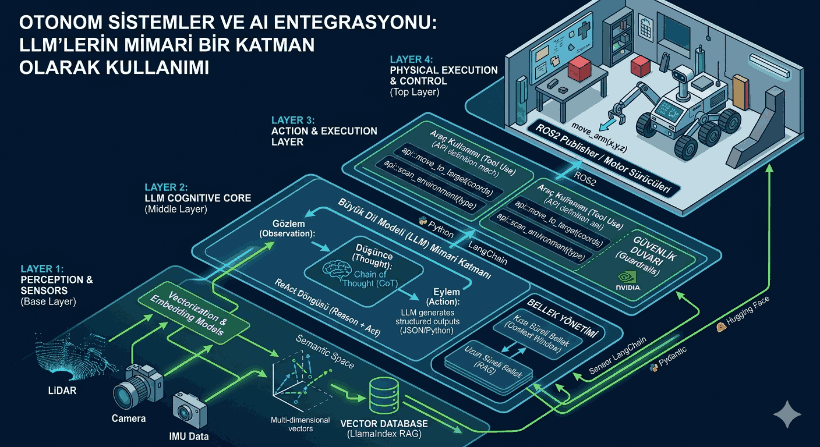
Figure 1: Autonomous Systems and AI Integration: Using LLMs as an Architectural Layer and Code Analysis
1. LLM-Based Autonomous Architecture Layers
In an autonomous system, the LLM functions not merely as a text interface, but as the “Prefrontal Cortex” of the system. This architecture generally consists of four main layers:
Perception and Vectorization Layer: The stage where sensor data (LiDAR, Camera, IMU) or unstructured text data is converted into numerical vectors (embeddings).
Cognitive Planning (Reasoning) Layer: The core where the LLM breaks down complex tasks into subtasks using “Chain of Thought” (CoT) protocols.
Memory Management: Manages the data flow between short-term memory (context window) and long-term memory (Vector Databases - RAG).
Action and Control Layer: The layer where LLM outputs (usually JSON or Python code) are transmitted to system calls or motor drivers (such as ROS2 nodes).
2. “Chain of Thought” and ReAct Approach in Autonomous Agents
The decision-making mechanism of LLMs in autonomous systems is generally built upon the ReAct (Reason + Act) paradigm. In this approach, the model first makes an observation, performs reasoning based on this observation, and then executes an action.
Technical Analysis: ReAct Cycle
In a scenario where a robotic arm sorts a complex object, the LLM follows this logical flow:
Thought: “There is a red cube and a blue cylinder on the table. I was asked to put the red cube into the box.”
Action:get_object_coordinates("red_cube") -> move_arm(x, y, z)
Observation: “The cube was gripped but the weight balance was disrupted.”
Thought: “I should optimize the grip angle by 15 degrees.”
3. Code Analysis: LLM Integration and Tool Use
In modern autonomous systems, LLMs interact via APIs or custom functions (tools) rather than controlling hardware directly. Below is an example of an autonomous agent prototype using the LangChain and Pydantic libraries in Python.
import os
from typing import List
from langchain.agents import Tool, AgentExecutor, LLMSingleActionAgent
from langchain.prompts import StringPromptTemplate
from langchain_openai import OpenAI
from pydantic import BaseModel, Field
# Class Defining the Autonomous System's CapabilitiesclassRobotController(BaseModel):
"""API providing direct control over robotic hardware."""defmove_to_target(self, coordinates: str):
# Sending commands to motor drivers at the hardware level (e.g., ROS2 Publisher) print(f"Moving to: {coordinates}")
return"Target reached."defscan_environment(self, sensor_type: str):
# LiDAR or Camera data analysis print(f"Scanning environment with {sensor_type}...")
return"No obstacles detected."# Defining the tools the LLM can usecontroller = RobotController()
tools = [
Tool(
name="Navigator",
func=controller.move_to_target,
description="Enables the robot to move to specific coordinates." ),
Tool(
name="Scanner",
func=controller.scan_environment,
description="Detects obstacles in the environment via sensors." )
]
# Prompt Engineering: Defining the system's behavioral boundariestemplate ="""You are an autonomous exploration robot.
Your task is to reach given targets safely.
You have access to the following tools: {tools}Flow:
Question: The task you need to perform
Thought: Think about what you need to do
Action: Tool to use [{tool_names}]
Action Input: Data to be sent to the tool
Observation: The tool's result
... (this Thought/Action/Observation cycle can be repeated 3 times)
Thought: I now know the final answer.
Final Answer: The completion status of the task.
Task: Go to the side of the table in the kitchen and scan the path.
"""
In this code block, the LLM is not just assigned the task of generating text; it is also assigned “functions” such as Navigator and Scanner that interact with the physical world. This is the foundation of the Functional Call mechanism in autonomous systems.
4. Software Resources and Critical Libraries
The libraries that have become industry standards in autonomous systems and AI integration are as follows:
LangChain / LangGraph: Used for complex agent loops and state management. LangGraph, in particular, allows autonomous processes to be modeled as a cyclic graph rather than a “Directed Acyclic Graph” (DAG).
AutoGPT / BabyAGI: Pioneers of autonomous task management and self-goal-setting algorithms.
Hugging Face Transformers / Accelerate: Enables models to run optimized on local devices (Edge AI).
LlamaIndex (GPT Index): A RAG (Retrieval-Augmented Generation) library that optimizes the autonomous system’s interaction with its “knowledge base” (PDFs, sensor logs, databases).
ROS2 (Robot Operating System): Middleware software that converts LLM outputs into physical robot movements. Communication with embedded systems is provided via micro-ROS.
5. Disadvantages of LLMs as an Architectural Layer and the “Guardrails” Mechanism
The use of LLMs in autonomous systems can lead to critical security vulnerabilities due to the risk of Hallucination. It could be catastrophic for a robotic system to perceive a non-existent object as if it were present and perform a maneuver.
To minimize these risks, a Guardrails layer is used.
NVIDIA NeMo-Guardrails: Filters LLM outputs within specific policies.
Pydantic Output Parsing: Verifies at runtime whether the output from the LLM is in a specific data structure (e.g., a list of float coordinates).
Technical Note: To ensure determinism in autonomous systems, the LLM temperature is usually set to 0.0. This ensures that the model produces the highest probability (and most consistent) answer every time.
6. Future Perspective: Multimodal Autonomy
The autonomous systems of the future will be powered not just by text-based LLMs, but by VLMs (Vision-Language Models). These models can process images from a camera at the “token” level, enabling them to reason spatially without the need for text.
For example, Google RT-2 (Robotic Transformer 2) has combined the semantic knowledge of LLMs with the precision of robotic control by converting visual data directly into motor commands (tokenized actions).
Conclusion
Adding LLMs to autonomous systems as an architectural layer is the key to transitioning from “smart” systems to “conscious” (reasoning) systems. Code analysis and architectural approaches show that success lies not in the size of the model, but in how tightly and securely this model is integrated with physical world tools. For developers, the focus should no longer be just on model training, but on the “orchestration” layers that will run these models flawlessly in autonomous loops.