We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
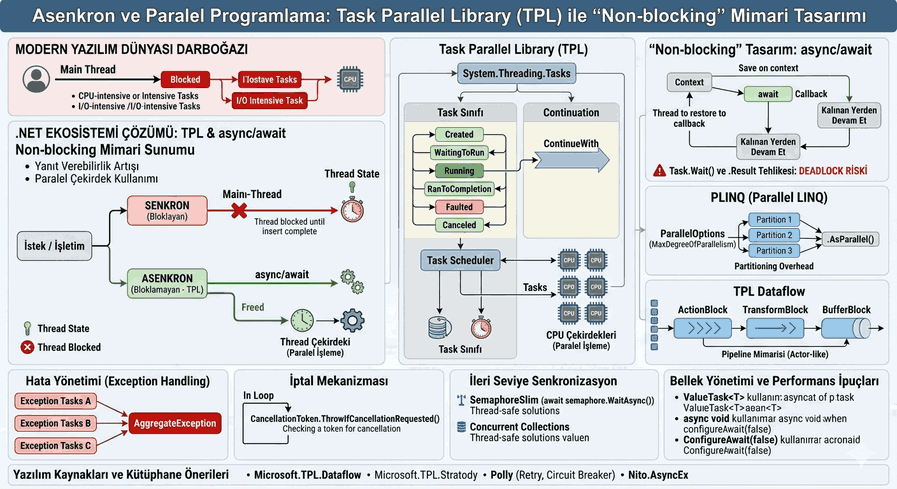
NoSQL Paradigm and Sharding: Partitioning Techniques for Managing Massive Datasets
In modern software architectures, the concept of “Big Data” has evolved from a buzzword into an operational necessity. When traditional RDBMS (Relational Database Management Systems) hit the limits of Vertical Scaling, the data reaching unmanageable sizes leads to performance bottlenecks. At this point, NoSQL databases and Sharding—the cornerstone of Horizontal Scaling—come into play.
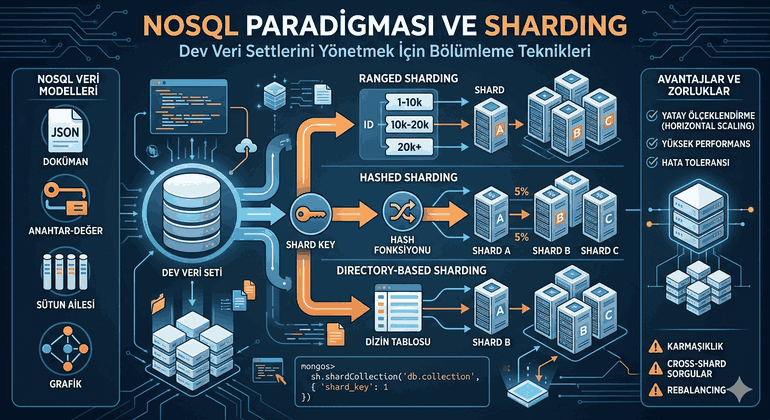
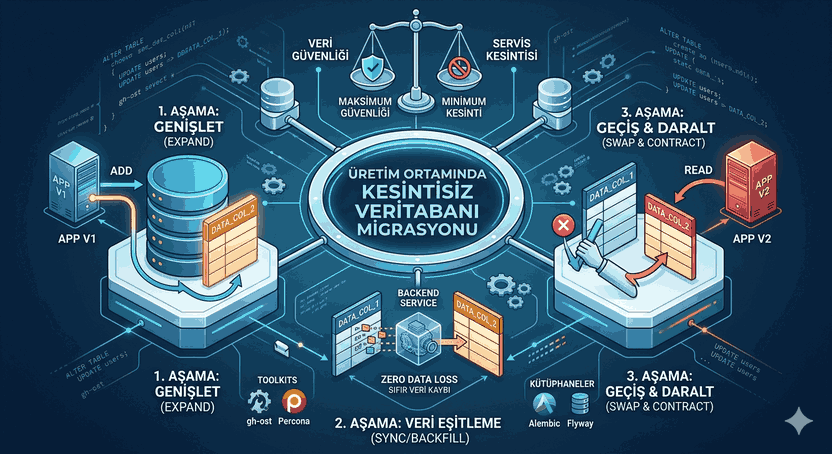
Figure 1: NoSQL Paradigm and Sharding: Partitioning Techniques for Managing Massive Datasets.
1. Data Modeling and Scalability in NoSQL Architecture
NoSQL provides flexibility by breaking the rigid schema structure with the “Not Only SQL” philosophy. However, the real purpose of this flexibility is to distribute data across multiple servers. In NoSQL systems, data is generally stored using Key-Value, Document, Column-Family, or Graph models.
Scalability is examined along two main axes:
Vertical Scaling (Up): Increasing the CPU, RAM, or disk capacity of the existing server. It is not sustainable due to physical limits and the cost curve.
Horizontal Scaling (Out): Distributing the load by adding new servers to the system. Sharding is the core mechanism of this approach.
2. What is Sharding? Logical and Physical Separation
Sharding is the process of breaking a single logical data set into pieces and distributing them to different physical nodes. Each piece is called a Shard. A shard behaves like an independent database on its own but holds only a subset of the total data set.
Shard Key Selection: The Key to Performance
The success of a sharding strategy depends on the efficiency of the chosen Shard Key. Choosing the wrong key leads to a situation called a “Hotspot,” where one server is overloaded and others remain idle.
3. Basic Partitioning Techniques
A. Ranged Sharding
Data is distributed based on specific ranges of the determined key. For example, User IDs between 1-10,000 go to Shard A, and 10,001-20,000 go to Shard B.
Advantage: Range queries are very fast.
Disadvantage: Data distribution can be uneven (e.g., new records are always written to the last shard).
B. Hashed Sharding
The Shard Key is passed through a hash function, and the corresponding Shard is determined based on the result.
Advantage: Data distribution is mathematically homogeneous. The risk of hotspot formation is low.
Disadvantage: Range queries are difficult because sequential data may be distributed across different servers.
C. Directory-Based Sharding
There is a central “Lookup Table” in the system that keeps track of where each piece of data is located.
Advantage: Flexible; data can be moved dynamically.
Disadvantage: The directory table can become a Single Point of Failure.
4. Technical Implementation: MongoDB and Sharding Configuration
MongoDB is one of the most popular document-based NoSQL databases that natively supports the sharding mechanism. A MongoDB Sharded Cluster consists of the following components:
Shard: A mongod instance that holds a data subset.
Config Servers: Hold cluster metadata.
Mongos (Router): Routes client requests to the appropriate shard.
Example Code: MongoDB Sharding Setup Steps
// 1. Enable sharding on a database basis
sh.enableSharding("corporate_data_center")
// 2. Determine a Shard Key for a collection (Hashed Sharding example)
// Distributing data via "user_id"
sh.shardCollection("corporate_data_center.users", { "user_id":"hashed" })
// 3. Check shard status
sh.status()
5. Software Resources and Libraries
The following tools and libraries are critical for deep expertise in the NoSQL and Sharding ecosystem:
Apache Cassandra: Offers a decentralized sharding structure using Consistent Hashing. High-performance data distribution can be managed with the Datastax Java Driver.
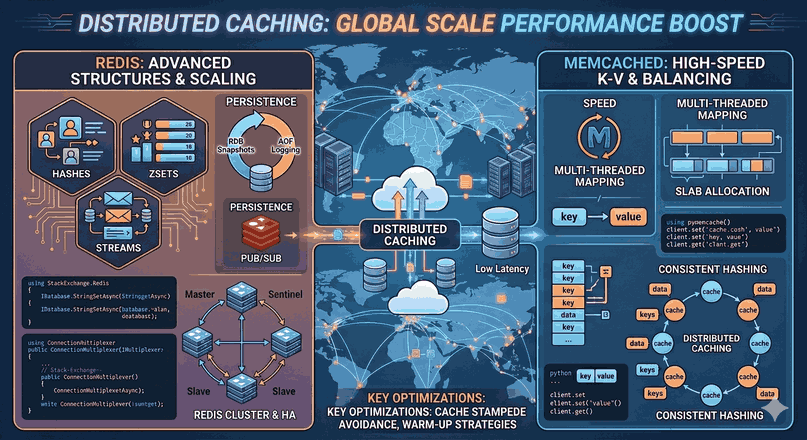
Redis Cluster: Provides sharding implementation for in-memory data distribution using Jedis or StackExchange.Redis libraries.
Vitess: A Kubernetes-native sharding system that provides NoSQL-like scalability on MySQL. It was developed to manage YouTube’s massive traffic.
Elasticsearch: Increases both search performance and high availability by dividing data into “Primary Shard” and “Replica Shard” structures.
6. Complexities and Solutions Brought by Sharding
Implementing sharding does not always provide “free” performance gains. Here are some of the engineering challenges it brings:
Cross-Shard Joins: Combining (Joining) data located in different shards is quite costly. In the NoSQL world, this is usually solved with Denormalization (storing data redundantly).
Rebalancing: When a shard is full or a new node is added, data must be moved. This process significantly affects network traffic and disk I/O.
Global Unique Keys: Auto-increment IDs do not work in a sharded structure. Instead, decentralized unique key generators like UUID, Snowflake ID (developed by Twitter), or ULID must be used.
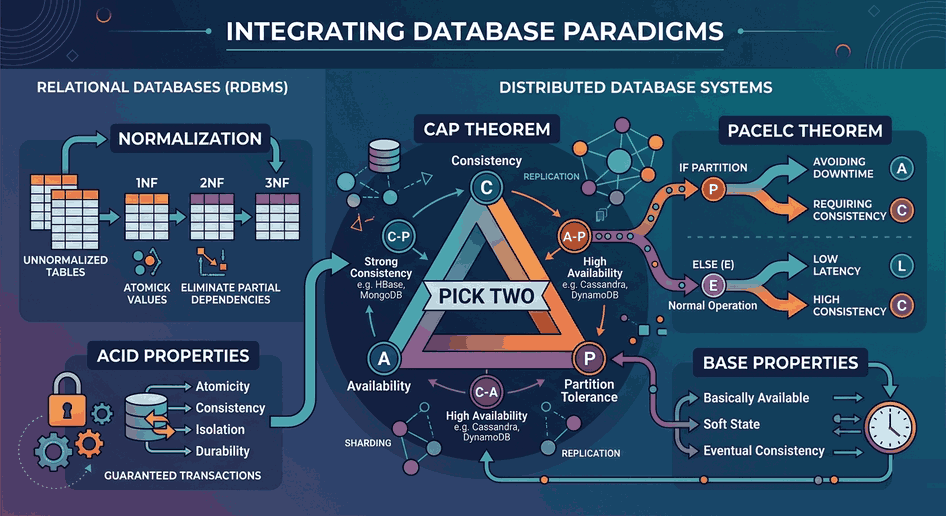
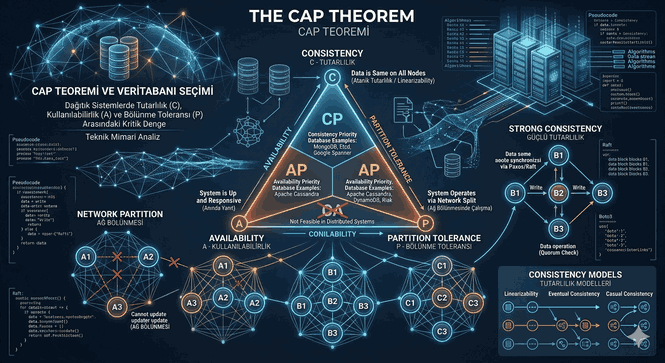
In a NoSQL system where sharding is applied, the CAP Theorem (Consistency, Availability, Partition Tolerance) is the deciding factor. It is impossible to provide both full consistency and 100% availability in a distributed system at the same time.
CP (Consistency/Partition Tolerance): MongoDB falls into this category by default. When a partition occurs, the system may stop write operations to maintain consistency.
AP (Availability/Partition Tolerance): Cassandra is in this structure. It adopts the “Eventual Consistency” model; data does not spread to all shards instantly, but within a short period of time.
Conclusion and Engineering Notes
Sharding is an inevitable technique for managing petabyte-scale data. However, before resorting to this method, ensure that vertical optimizations such as database indexing, query optimization, and caching (Redis/Memcached) have been exhausted.
Critical Notes:
Shard Key is Immutable: In most systems, changing a once-defined Shard Key requires moving all data, which can cause the system to be offline for days.
Over-Sharding: Creating more shards than necessary increases the metadata management overhead and raises latency.
Monitoring: Data imbalance (Skew) must be continuously checked using tools like Prometheus and Grafana to monitor data distribution between shards.
In the NoSQL world, sharding is not just a storage strategy but also an architectural decision that determines the application’s life cycle. With the right library selection and mathematically proven partitioning algorithms, systems achieve near-infinite scalability potential.