We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
Scalability in Software: High-Availability Design with Vertical and Horizontal Scaling
In today’s software ecosystems characterized by dynamic traffic loads, it is not enough for an application to simply be functional. A system’s ability to respond to increasing user counts and data volumes—that is, its scalability—is a critical parameter for the sustainability of a project. This blog post examines vertical and horizontal scaling techniques, load balancing mechanisms, and high-availability design principles in depth.
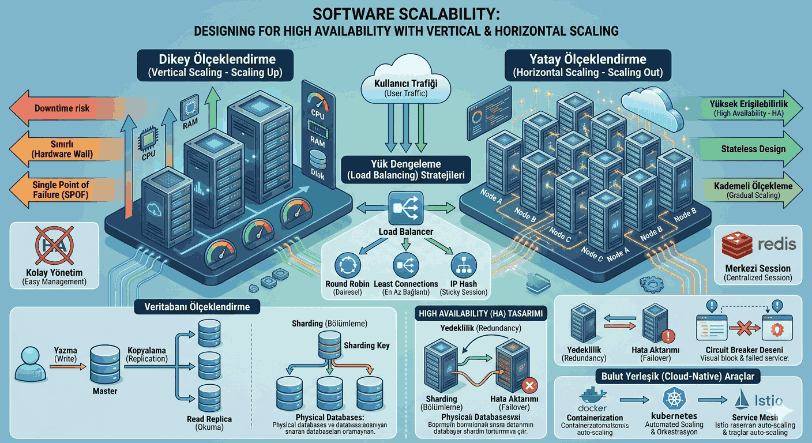
Figure 1: Scalability in Software: High-Availability Design with Vertical and Horizontal Scaling
1. Concept of Scalability and Performance Metrics
Scalability is a system’s ability to handle an increasing workload by adding resources. Performance and scalability are often confused; performance relates to how long a single request takes to be answered (latency), whereas scalability relates to how many requests per second (throughput) the system can successfully process.
Key Performance Indicators (KPIs):
Response Time: The time between sending a request and receiving a response.
Throughput: The total number of transactions processed per unit of time.
Resource Utilization: The percentage of CPU, RAM, and I/O resource usage.
2. Vertical Scaling (Scaling Up)
Vertical scaling is the method of gaining performance by increasing the capacity (CPU, RAM, Disk) of a single existing server.
Advantages and Disadvantages:
Easy Management: It does not require major changes in software architecture. Database configurations generally remain the same.
Inter-process Communication: Since data is on the same machine, there is no network latency.
Limitations: It hits hardware limits (Hardware Wall) after a certain point. Additionally, upgrading server hardware usually requires shutting down the system (Downtime).
Single Point of Failure (SPOF): Dependence on a single powerful server means the entire system stops if that server crashes.
3. Horizontal Scaling (Scaling Out)
Horizontal scaling is based on the principle of distributing the workload by adding more servers (nodes) to the system. It forms the basis of modern microservices architectures and the world of Cloud Computing.
Horizontal Scaling at the Application Layer
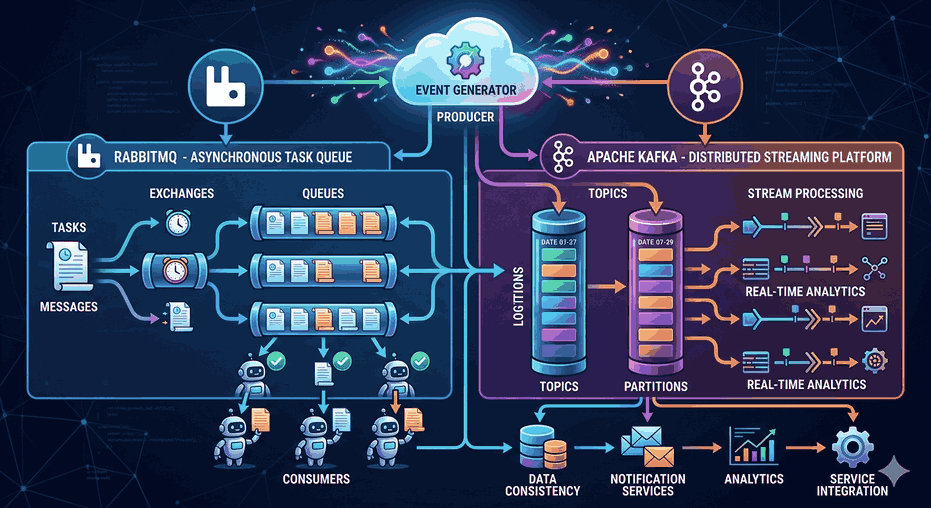
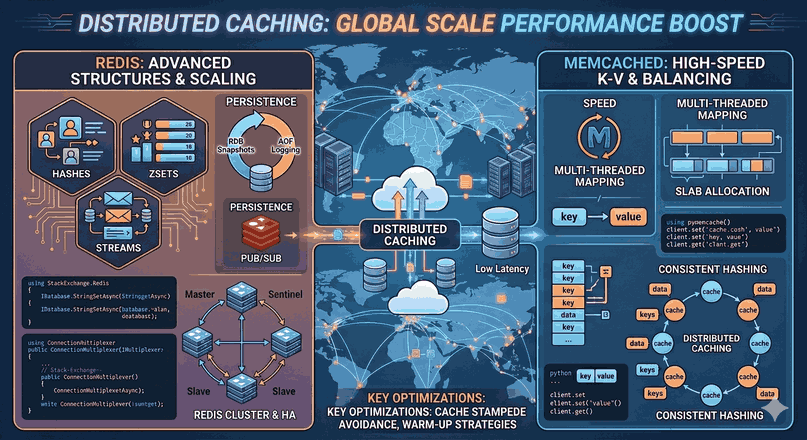
For an application to be horizontally scalable, it must be designed as Stateless. User session information should not be held in the application server but in a centralized cache mechanism (Redis, Memcached).
Example: Stateless Session Management with Python/FastAPI (Redis)
from fastapi import FastAPI, Depends
import redis
app = FastAPI()
# Redis connection poolr = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
defget_session_data(session_id: str):
# Data is fetched from Redis instead of local memory data = r.get(f"session:{session_id}")
return data
@app.get("/profile")
asyncdefread_profile(session_id: str):
user_data = get_session_data(session_id)
return {"user": user_data, "server": "Node_A"}
Horizontal Scaling at the Database Layer
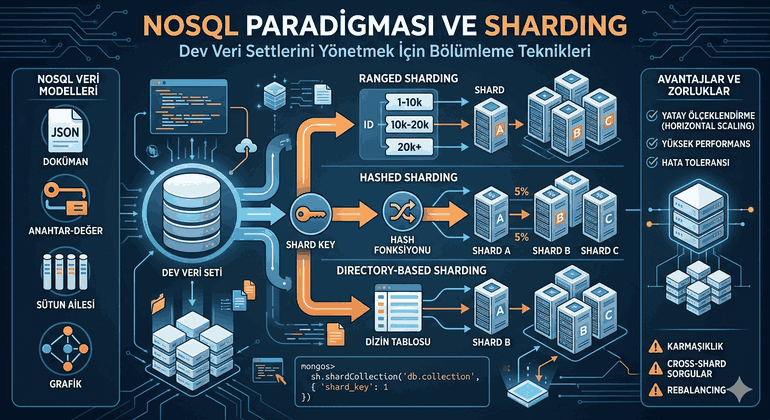
Scaling databases horizontally is more complex than the application layer. This is where Sharding and Replication come into play.
Database Sharding: Dividing data into different physical databases based on a specific key (sharding key).
Read Replicas: Distributing write operations to a master server (Master) and read operations to copies (Slave/Replica).
4. Load Balancing Strategies
In a horizontally scaled structure, the Load Balancer determines how incoming requests are distributed to servers.
Algorithms:
Round Robin: Sends requests to servers in turns.
Least Connections: Selects the server with the fewest active connections.
IP Hash: Ensures that the user is always directed to the same server based on their IP address (Sticky Sessions).
Nginx Configuration Example:
http {
upstreammy_backend_cluster {
least_conn; # Direct to the server with the least connections
server 10.0.0.1:8080weight=3;
server 10.0.0.2:8080;
server 10.0.0.3:8080backup; # Kicks in if others crash
}
server {
listen80;
location/ {
proxy_passhttp://my_backend_cluster;
}
}
}
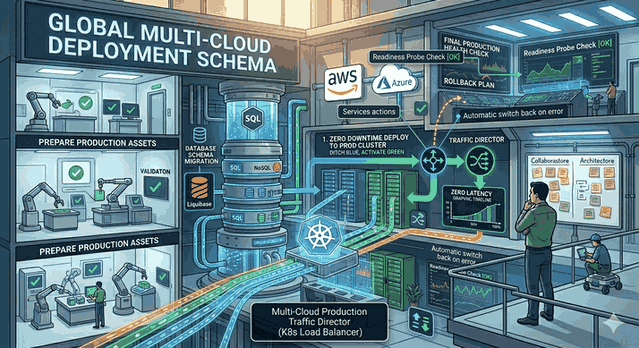
5. High Availability (HA) Design
High Availability is a system’s ability to provide uninterrupted service over an agreed-upon time period (e.g., 99.999% - Five Nines). Redundancy is essential for HA design.
Critical Components for HA:
Health Checks: The load balancer must constantly check whether the servers behind it are healthy.
Failover Mechanisms: The automatic redirection of traffic to a backup when a component crashes.
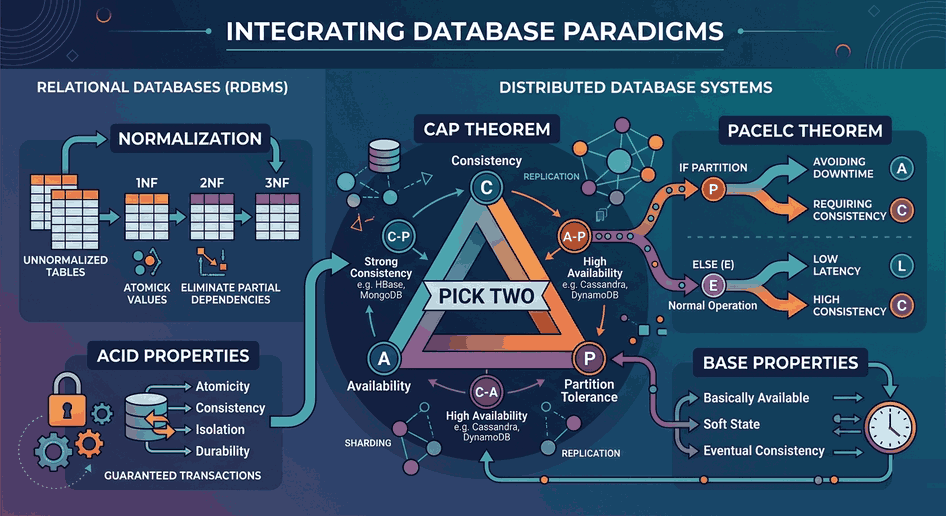
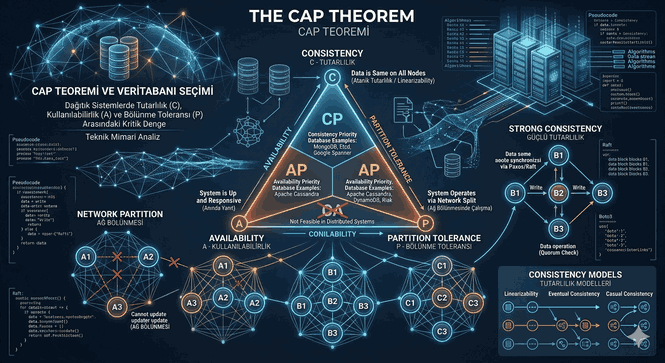
Data Consistency: In distributed systems, a balance between consistency and availability must be established within the framework of the CAP theorem (Consistency, Availability, Partition Tolerance).
Circuit Breaker Pattern
In distributed systems, continuing to send requests to a crashed service causes resource exhaustion. The Circuit Breaker protects the rest of the system by cutting off traffic to the faulty service.
Java/Spring Boot and Resilience4j Example:
@CircuitBreaker(name ="inventoryService", fallbackMethod ="fallbackInventory")
public ProductDetails getProductDetails(String productId) {
return inventoryClient.getInventory(productId);
}
public ProductDetails fallbackInventory(String productId, Throwable t) {
// Return default or cached data if the service is downreturnnew ProductDetails(productId, "N/A", 0);
}
6. Cloud-Native Scaling Tools
In modern architectures, scaling is not done manually. Containerization and orchestration tools automate this process.
Docker: Packages the application and its dependencies into an isolated unit.
Kubernetes (K8s): Enables automatic scaling of containers (Horizontal Pod Autoscaler - HPA).
Service Mesh (Istio, Linkerd): Manages traffic, security, and observability between microservices.
Kubernetes HPA (Horizontal Pod Autoscaler) Definition:
7. Advanced Scaling at the Database Level: NoSQL vs. SQL Comparison
Database selection is of vital importance in discussions of scalability.
Relational (SQL): More prone to vertical scaling due to ACID compliance. However, systems like PostgreSQL and MySQL can be made horizontally scalable with tools like Vitess (developed by YouTube) or Citus.
NoSQL (Cassandra, MongoDB, DynamoDB): Focused on horizontal scaling (Partitioning) by design. Ideal for massive datasets.
Note: There is no “Silver Bullet” in software architecture. While vertical scaling is advantageous at the beginning in terms of cost/time, horizontal scaling is inevitable for a system at a global scale.
Conclusion
Creating high-traffic and mission-critical applications requires thinking about scalability at every layer of the infrastructure. By using stateless structures at the application layer, replication and sharding strategies at the database layer, and design patterns like intelligent load balancers and circuit breakers at the network layer; one can build systems that are both high-performing and never crashing (High Availability).
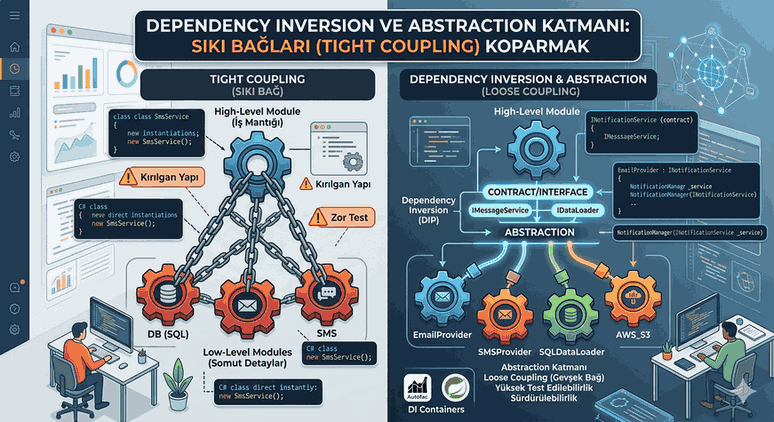
It should not be forgotten that the best scaling system is not the one with the fewest components, but the one that has minimized the dependency (tight coupling) between its components and is self-healing in case of failure.