We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
Writing CPU Cache Friendly Code: Spatial and Temporal Locality Principles
In software performance optimization, the most critical bottleneck is often not computational power, but the speed at which data is delivered to the processor. While modern CPUs have massive processing capacities measured in microseconds, retrieving data from main memory (RAM) is quite slow by comparison. At this point, “Cache Friendly” coding is the fundamental factor that determines whether a piece of software can reach its theoretical speed limits.
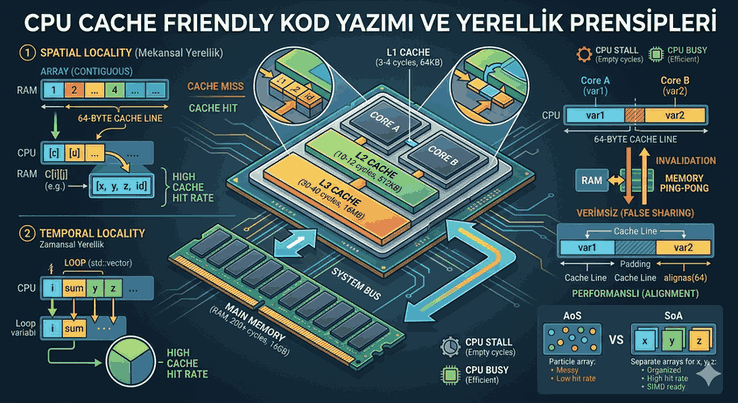
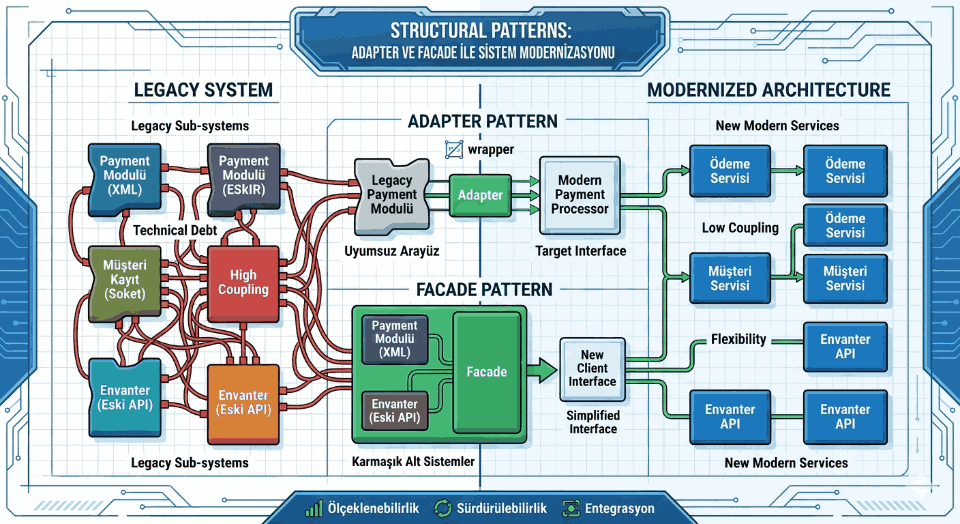
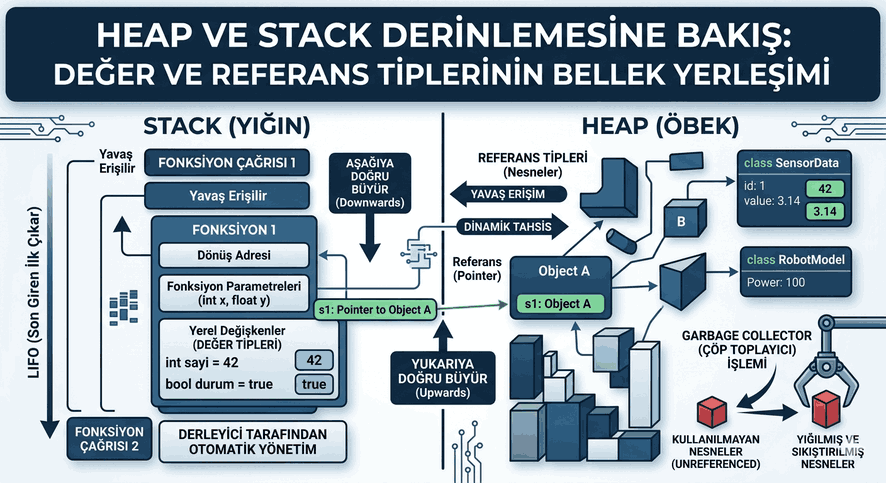
Figure 1: Writing CPU Cache Friendly Code: Spatial and Temporal Locality Principles.
1. Memory Hierarchy and the Concept of Latency
In processor architectures, data access times follow a layered structure. The L1 cache is the closest and fastest to the processor; it is followed by L2 and L3. RAM is located at the very end of this hierarchy, in the “high latency” zone.
L1 Cache: Access time of approximately 3-4 cycles.
L2 Cache: Access time of approximately 10-12 cycles.
L3 Cache: Access time of approximately 30-40 cycles.
Main Memory (RAM): Access time of 200+ cycles.
If a CPU cannot find the data it needs in the cache (Cache Miss), it remains idle for hundreds of processing cycles. This situation is called a “Stall.” The goal of cache-friendly coding is to minimize these waits.
2. Principles of Locality
There are two main principles of locality that optimize performance in memory management:
A. Temporal Locality
If a data point has been accessed, there is a high probability that the same data will be accessed again in the near future. Variables within loops or frequently used function parameters fall into this class. Cache algorithms attempt to keep the most recently used data (LRU - Least Recently Used) in the fast access layer.
B. Spatial Locality
If a data point has been accessed, there is a high probability that data located immediately adjacent to it in memory will also be accessed in a short time. The CPU does not fetch data as a single byte, but usually in 64-byte blocks (Cache Line). If your data is sequential in memory, the next data will already be fetched into the cache when you access it.
3. Cache Line Concept and Alignment
Fixed-size packets called “Cache Lines” are used when transferring data from RAM to the cache. In modern x86 and ARM architectures, this is usually 64 bytes.
Important Note: If a data structure (struct) straddles a 64-byte boundary, the processor must load two separate cache lines to read this data. This is known as a “Cache Line Split” and degrades performance. This is why aligning data structures with commands like alignas or __attribute__((aligned(64))) is critical.
4. Data Access in Matrix Operations: A Practical Analysis
The most classic example of cache-friendly coding is traversing two-dimensional arrays (matrices). In “Row-Major” languages like C++, memory is laid out row by row.
Cache-Unfriendly Approach (Column-Major)
// Inefficient: Column-based traversal
for (int j =0; j <1000; j++) {
for (int i =0; i <1000; i++) {
sum += matrix[i][j]; // Large jumps are made in memory at each step
}
}
In the code above, the traversal moves to the next row at each inner loop step. If the distance between them is greater than a cache line, each access results in a “Cache Miss.”
Cache-Friendly Approach (Row-Major)
// Efficient: Row-based traversal
for (int i =0; i <1000; i++) {
for (int j =0; j <1000; j++) {
sum += matrix[i][j]; // Sequential memory access, high Spatial Locality
}
}
Here, when the processor fetches the first element, it also caches the 63 bytes next to it (a total of 16 4-byte integers). The next 15 accesses are free.
5. Data-Oriented Design (DOD) and SoA vs AoS
Object-oriented programming (OOP) groups data within objects (Array of Structures - AoS). However, in performance-oriented systems, separating data based on processing requirements (Structure of Arrays - SoA) is preferred.
AoS (Array of Structures)
structParticle {
float x, y, z;
int id;
char name[32];
};
Particle particles[1000];
If you are performing a calculation using only the x, y, z coordinates, the name and id fields will also fill up the cache line. This means 80% of the cache is occupied by unnecessary data.
In an SoA structure, the processor only loads the coordinate arrays that are needed. This structure is also ideal for the use of SIMD (Single Instruction Multiple Data) instruction sets (AVX, SSE).
6. Linked List vs Array (Choosing a Data Structure)
Although std::list (Linked List) is logically ordered, its nodes are scattered across different locations in memory (Heap fragmentation). Pointer chasing requires resolving a new memory address at each step and disrupts the prefetcher mechanism.
In contrast, std::vector (Array) keeps data in blocks. If you want to write cache-friendly code, using std::vector will always yield faster results, even with the cost of dynamic searching and insertion.
7. The False Sharing Phenomenon
In multi-core systems, different cores trying to modify different variables located on the same cache line leads to a performance disaster.
Scenario: Core A updates struct.var1; Core B updates struct.var2.
Problem: If both variables are within the same 64-byte cache line, when one core updates the data, the cache line in the other core is considered “invalid.” Data is constantly re-read from RAM due to Cache Coherency protocols.
Solution: Adding padding between critical variables or using alignment to move them to different cache lines.
8. Software Libraries and Tools
The following tools are industry standards for performance analysis and cache-friendly coding:
Valgrind (Cachegrind): Simulates the program’s cache usage and reports Miss rates.
Intel VTune Profiler: Uses processor hardware counters to identify bottlenecks at the micro-architecture level.
Perf (Linux): Used to monitor CPU hardware events (cache-misses, instructions per cycle).
Google Benchmark: A library used to measure the CPU time and memory performance of code snippets.
9. Advanced Techniques: Cache Blocking (Tiling)
In large datasets, if the entire data does not fit into the L3 cache, the “Tiling” technique is applied. The dataset is divided into small blocks (tiles) that fit into the cache, and operations on each block are completed before moving on to the next. This maximizes Temporal Locality.
// Blocking example for matrix multiplication (Simplified)
for (int bi =0; bi < N; bi += BLOCK_SIZE) {
for (int bj =0; bj < N; bj += BLOCK_SIZE) {
for (int bk =0; bk < N; bk += BLOCK_SIZE) {
// Inner loops process within the block
for (int i = bi; i < bi + BLOCK_SIZE; i++) {
for (int j = bj; j < bj + BLOCK_SIZE; j++) {
for (int k = bk; k < bk + BLOCK_SIZE; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
}
}
}
10. Conclusion and Recommendations
In modern hardware, performance is measured not just by algorithmic complexity ($O(n)$), but by how fast the hardware can access data. For cache-friendly coding:
Keep your data contiguous in memory.
Minimize pointer usage, and prefer arrays of value types.
Group frequently used data into small structures (SoA approach).
Be careful of False Sharing in multi-core systems.
Optimize critical loops according to Data Alignment.
It should be remembered that the fastest code is code where the processor does not have to wait for data. Designing software architecture with the memory hierarchy in mind from the beginning is the foundation for performance gains achieved in the later stages of a project.