We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
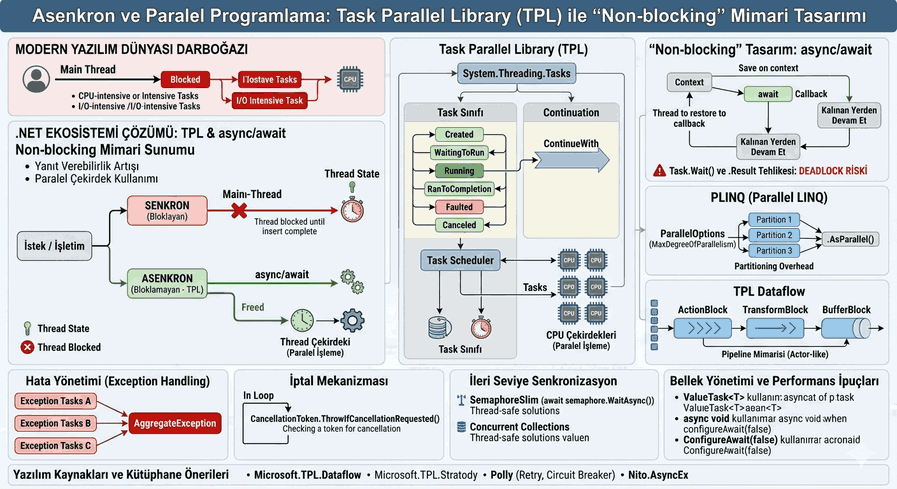
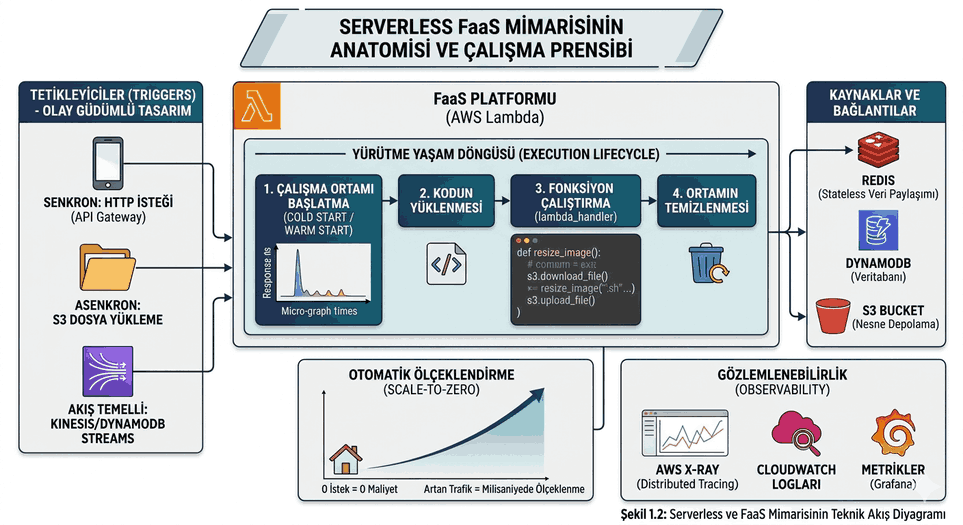
Concurrency Patterns: Lock Mechanisms and Race Condition Management in Multi-thread Environments
With the increasing performance requirements in the software world, fully utilizing the capacity of multi-core processors has become a necessity. Parallel computing and concurrency are key to leveraging this capacity. However, managing threads that attempt to access shared resources simultaneously brings complex scenarios and potential errors.
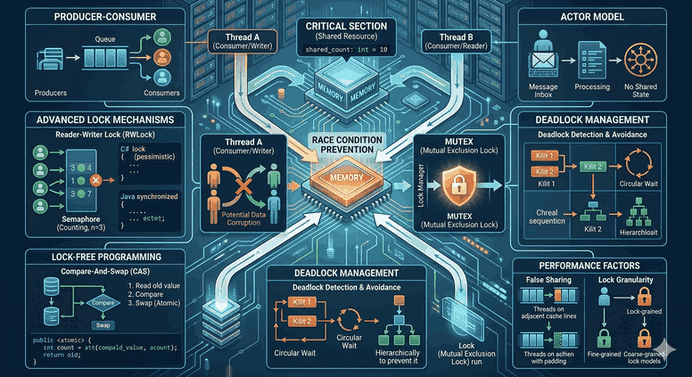
Figure 1: Concurrency Patterns: Lock Mechanisms and Race Condition Management in Multi-thread Environments.
1. Dangers of Shared State: Race Condition and Critical Section
The biggest problem underlying concurrency management is the Race Condition. A race condition is a situation where two or more threads access shared data simultaneously and at least one of them performs a write operation, causing the final result to change depending on the scheduling of the threads.
The Concept of Critical Section
The part of the code where the application accesses a shared resource and this access must be atomic is called the Critical Section. If this region is not properly protected, data integrity is compromised.
Example Scenario (C#):
publicclassCounter {
privateint _count = 0;
publicvoid Increment() {
_count++; // This operation is actually not atomic.// 1. Read the value// 2. Modify the value// 3. Write the value back }
}
The simple increment operation above consists of three low-level steps. If two threads perform a “Read” at the same time, they both see the same old value, and ultimately only 1 increment occurs instead of the expected 2.
2. Lock Mechanisms and Synchronization Primitives
The most common method used to prevent threads from conflicting with each other is Mutual Exclusion (Mutex).
2.1. Mutex and Lock Keyword
A Mutex ensures that a resource is used by only one thread at a time. In modern languages, this is usually abstracted by lock (C#) or synchronized (Java) blocks.
Pessimistic Locking: It is assumed that a resource will always be subject to conflict, and the resource is locked until the operation is completed.
2.2. Semaphore and SemaphoreSlim
A Semaphore allows a specific number of threads to access a resource. It is ideal for a database connection pool or limited-capacity queue management.
Binary Semaphore: Takes only 0 and 1 values (similar to Mutex, but the concept of ownership is different).
Counting Semaphore: Allows “n” number of specified threads to pass.
2.3. Reader-Writer Locks (RWLock)
It is used to optimize performance in scenarios where read operations are much more frequent than write operations.
Allows multiple threads to read at the same time.
When a write operation begins, it blocks both other writers and all readers.
3. Lock-Free Programming and Atomic Operations
The use of locks brings risks such as “Deadlock” and “Thread Starvation”. Additionally, lock mechanisms lead to “Context Switch” costs at the operating system level. To avoid this cost, Lock-Free techniques and atomic operations are used.
CAS (Compare-And-Swap) Algorithm
The heart of lock-free data structures is the CAS operation. It checks if the value at a memory address matches an expected value; if it matches, it updates the value with the new one. This operation is atomic at the hardware level.
C++ Atomic Example:
#include<atomic>#include<thread>std::atomic<int> counter(0);
voidsafe_increment() {
for (int i =0; i <1000; ++i) {
counter.fetch_add(1, std::memory_order_relaxed);
}
}
4. Deadlock Analysis and Avoidance Strategies
Deadlock is a situation where the system locks up because two or more threads are waiting for locks held by each other. For a deadlock to occur, the “Coffman Conditions” (Mutual Exclusion, Hold and Wait, No Preemption, Circular Wait) must be met.
Deadlock Avoidance Methods:
Lock Ordering: Ensuring that all threads always acquire locks in the same order (e.g., lock A, then lock B).
Lock Timeout: Instead of waiting forever while waiting for a lock, giving up after a certain period (like Monitor.TryEnter).
Deadlock Detection: Detecting and intervening in cycles by analyzing lock graphs at runtime.
5. Modern Concurrency Patterns
When traditional lock mechanisms become difficult to manage, higher-level patterns come into play.
5.1. Actor Model
In this model, threads do not directly access shared data. Instead, each piece of data is managed by an “Actor,” and other units send messages to the actor to modify this data. (e.g., Erlang, Akka.NET, Orleans).
Advantage: No need for lock management; state isolation is achieved.
5.2. Producer-Consumer Pattern
This is where threads producing data (Producers) and threads processing data (Consumers) communicate via a thread-safe queue (BlockingCollection, ConcurrentQueue).
Provides load balancing.
Makes system components loosely coupled.
5.3. Double-Check Locking
It is an optimization method used for the thread-safe initialization of patterns like Singleton.
Java Example:
publicclassSingleton {
privatestaticvolatile Singleton instance;
publicstatic Singleton getInstance() {
if (instance ==null) { // First checksynchronized (Singleton.class) {
if (instance ==null) { // Second check instance =new Singleton();
}
}
}
return instance;
}
}
6. Memory Models and Visibility
In multi-threaded environments, using locks alone is not enough; when a change made by one thread is visible to other threads is also critical.
Volatile Keyword
The volatile keyword ensures that the variable’s value is always read from the main memory. It prevents inconsistency between CPU caches. However, it should be remembered that volatile provides visibility, not atomicity.
Memory Barriers (Fence)
These are barriers that prevent the processor and compiler from changing instruction reordering for performance optimization.
7. Popular Software Libraries and Tools
Optimized tools for concurrency management exist in different ecosystems:
C++:std::mutex, std::future, std::atomic (C++11 and later).
Go: Goroutines and Channels (CSP - Communicating Sequential Processes model).
Rust: A memory management model that prevents data races at compile-time thanks to “Ownership” and “Borrowing” rules.
8. Notes for Performance and Scalability
Lock Granularity: The narrower the scope of the lock (fine-grained), the less contention. However, managing too many small locks also increases complexity.
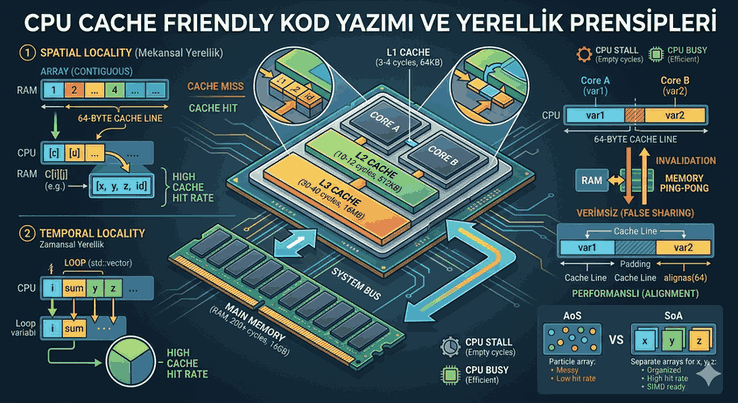
False Sharing: This is a performance loss that occurs when different threads update different variables while these variables are on the same CPU cache line. It can be solved by adding padding between variables.
Thread Pool Usage: Creating a new thread for every operation is costly. The load of context switching should be minimized by using existing thread pools.
Conclusion
Managing concurrency and parallelism is one of the most challenging areas of modern software engineering. Lock mechanisms used to prevent race conditions can lead to performance bottlenecks or deadlocks if not implemented correctly. Software architects should choose which of the locked, lock-free, or message-based (actor model) approaches will provide the most optimal result according to the project’s needs, while also considering hardware-level interactions.
The golden rule for a safe and scalable system is this: Minimize shared state; if you cannot, protect it with a disciplined synchronization strategy.