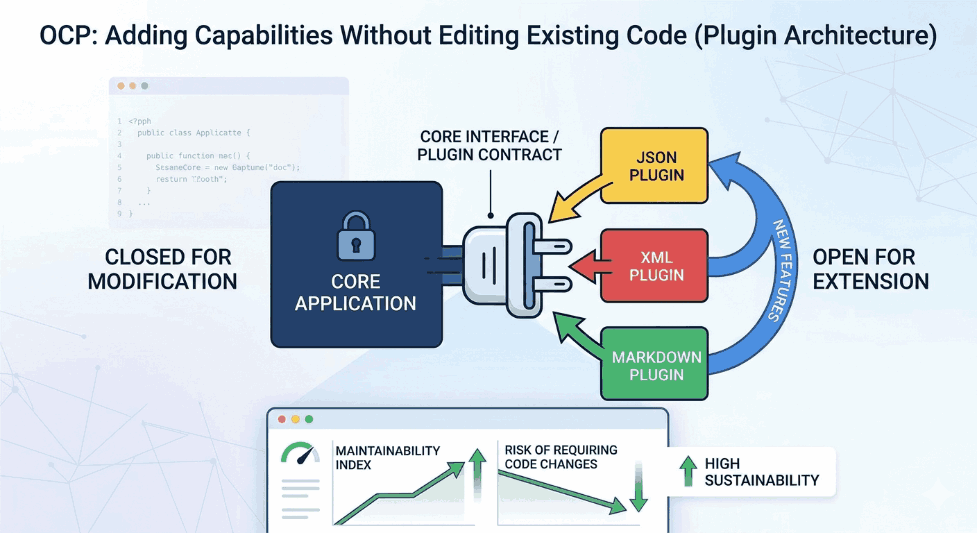
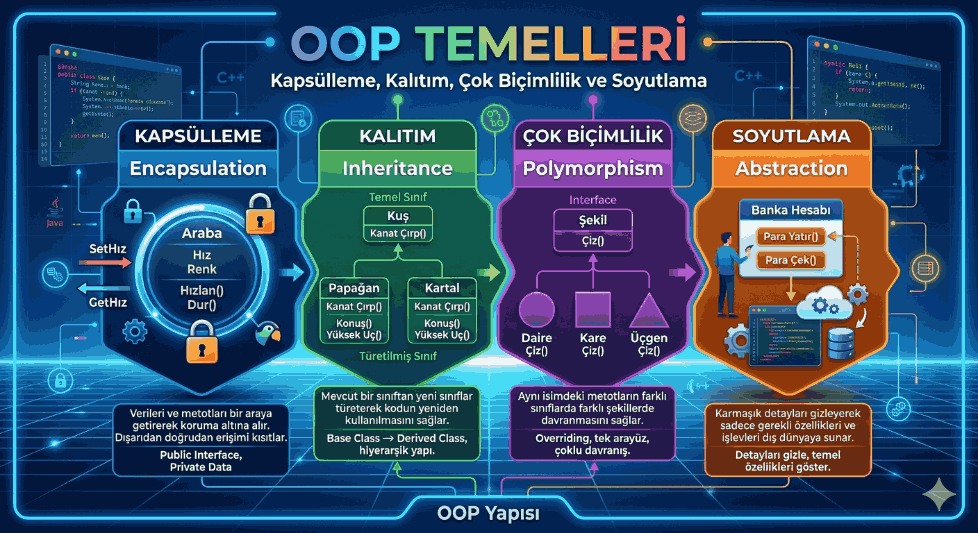
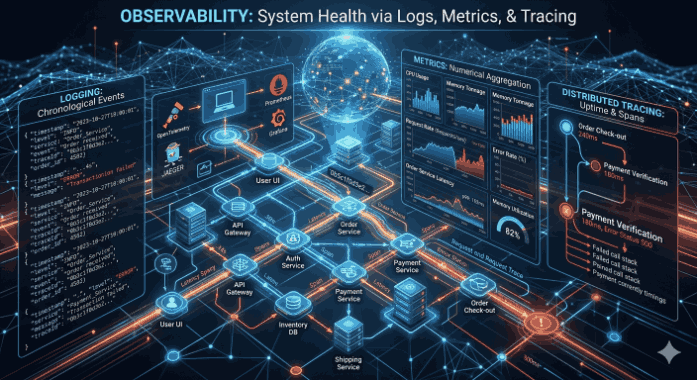
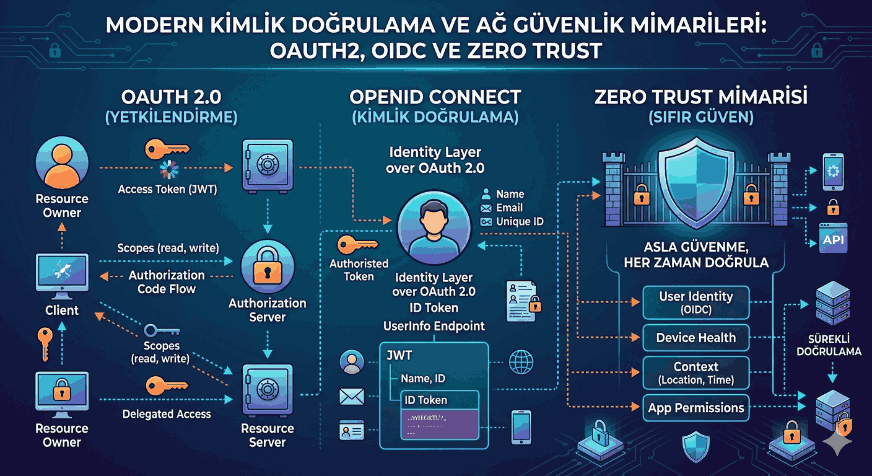
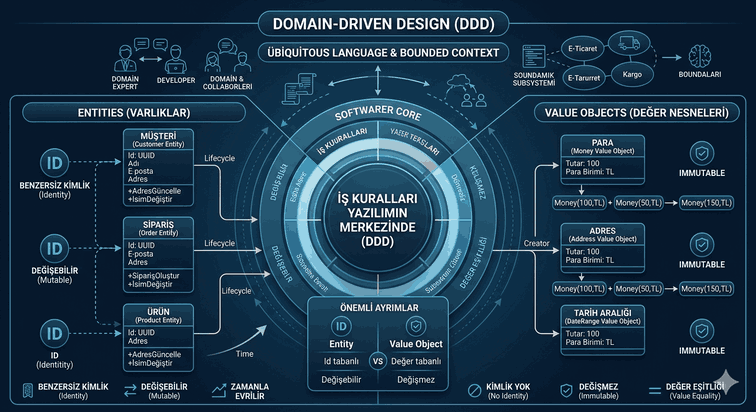
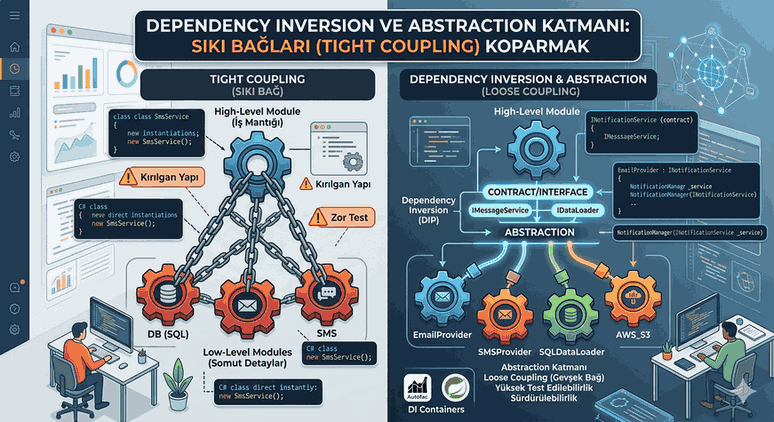
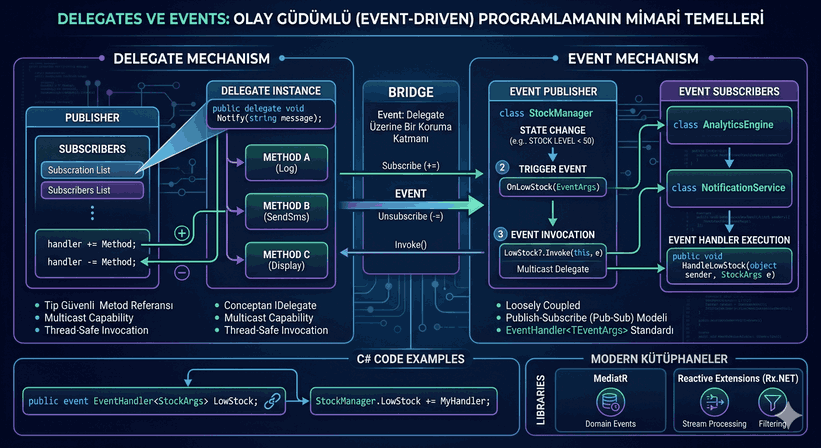
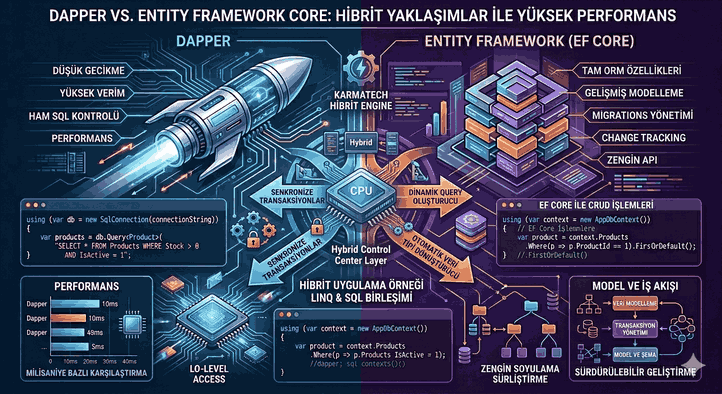
We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
Distributed Caching: Performance Boost at Global Scale with Redis and Memcached
In modern microservice architectures and high-traffic web applications, minimizing latency, reducing the load on databases, and ensuring scalability are strategic imperatives. This article examines the technical depths, architectural differences, and implementation strategies of industry-standard technologies: Redis and Memcached.
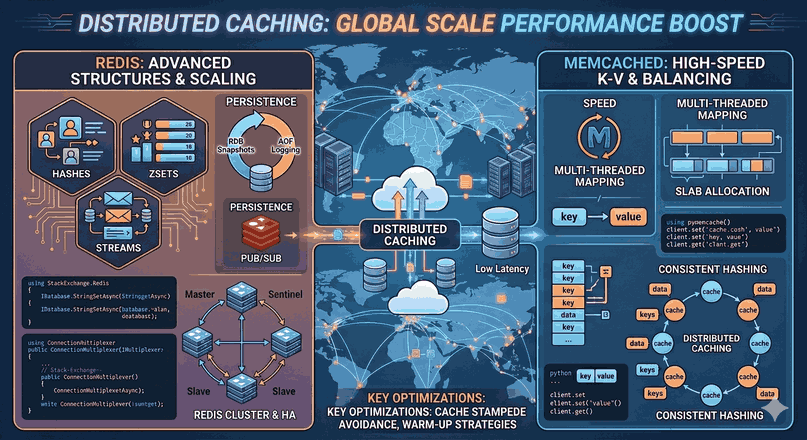
Figure 1: Distributed Caching: Performance Boost at Global Scale with Redis and Memcached.
1. Fundamentals of Distributed Caching Architecture
Distributed caching is the storage of data in RAM (Random Access Memory) across multiple server nodes. The difference from traditional “in-memory” caching is that the data is not tied to the application server and is provided as a centralized service in a clustered structure.
Core Cache Strategies
Cache-Aside (Lazy Loading): The application checks the cache first. If the data is missing (miss), it reads from the database and writes to the cache.
Write-Through: Data is written to the cache first, then simultaneously saved to the database. Data integrity is high.
Write-Behind (Write-Back): Data is written to the cache, and the write operation to the database is performed asynchronously at specific intervals. Performance is at the highest level, but it carries a risk of data loss.
2. Redis: Advanced Data Structures and Persistence
Redis (Remote Dictionary Server) is not just a key-value store, but an in-memory data structure server that supports advanced data types.
Technical Characteristics
Single-Threaded Event Loop: Redis uses a single thread for network I/O and command processing. This provides high speed by eliminating the complexity of lock mechanisms.
Data Persistence:
RDB (Redis Database Backup): Takes a snapshot of the dataset at specific time intervals.
AOF (Append Only File): Logs every written command to a file.
Pub/Sub Support: Built-in for real-time messaging and event-driven architectures.
Data Structures and Use Cases
Hashes: Ideal for object storage. (E.g., User profiles)
3. Memcached: Pure Performance and Multi-Threaded Structure
Memcached is designed for simplicity and high performance. Unlike Redis, it has a multi-threaded structure.
Technical Characteristics
Slab Allocation: To prevent fragmentation in memory management, it divides memory into pre-determined blocks (slabs).
LRU (Least Recently Used): Automatically deletes the least recently used data when memory is full.
Simple Data Model: Supports only String and Binary data types. Complex data structures must be serialized and stored at the application layer.
4. Technical Comparison: Redis vs. Memcached
Feature
Redis
Memcached
Architecture
Single-threaded
Multi-threaded
Data Structures
List, Set, Hash, Bitmaps, Geo
String/Blob only
Persistence
Yes (AOF/RDB)
No (Volatile)
Replication
Master-Slave
No (Requires third-party tools)
Scaling
Redis Cluster
Client-side hashing (Consistent Hashing)
5. Application Example: .NET Core and StackExchange.Redis
In a high-performance .NET application, Redis integration is usually done with the StackExchange.Redis library. The example below demonstrates the use of Multiplexer and data serialization techniques.
using StackExchange.Redis;
using System.Text.Json;
publicclassRedisCacheService{
privatereadonly ConnectionMultiplexer _redis;
privatereadonly IDatabase _db;
public RedisCacheService(string connectionString)
{
// Multiplexer should be managed as a singleton. _redis = ConnectionMultiplexer.Connect(connectionString);
_db = _redis.GetDatabase();
}
publicasync Task SetCacheAsync<T>(string key, T value, TimeSpan expiration)
{
var jsonData = JsonSerializer.Serialize(value);
await _db.StringSetAsync(key, jsonData, expiration);
}
publicasync Task<T?> GetCacheAsync<T>(string key)
{
var jsonData = await _db.StringGetAsync(key);
return jsonData.IsNullOrEmpty ? default : JsonSerializer.Deserialize<T>(jsonData);
}
}
6. Python and Memcached Integration
On the Python side, the pymemcache library provides Memcached access with low overhead.
from pymemcache.client import base
defmanage_memcached():
# Memcached connection settings client = base.Client(('localhost', 11211))
# Setting data (TTL: 3600 seconds) client.set('user_session_101', 'active_status', expire=3600)
# Getting data result = client.get('user_session_101')
if result:
print(f"Session Status: {result.decode('utf-8')}")
manage_memcached()
7. Performance Strategies at Global Scale
For applications operating at a global scale, it is not enough for the cache to be only in a central location. Geo-Replication and Multi-Region strategies come into play.
Consistent Hashing
When scaling cache servers horizontally (sharding), the distribution of keys to servers is critical. The standard key % n algorithm causes the entire cache to be invalidated when a server is added or removed. Consistent Hashing ensures that only a small portion of the data is remapped, preserving the cache hit rate.
Redis Cluster and Sentinel
Redis Sentinel: Provides High Availability. It makes the slave a master when the master node crashes.
Redis Cluster: Automatically divides data into 16,384 slots and distributes it across different nodes. It increases both read and write capacity horizontally.
8. Optimization and Anti-Patterns
Common technical mistakes made when implementing distributed caching can significantly degrade system performance.
Cache Stampede (Thundering Herd)
When thousands of requests demand an expired key at the same time, all requests are directed to the database simultaneously.
Solution: “Background Refresh” mechanisms that refresh data in the background or the use of locks (mutex).
Big Keys
Since Redis is single-threaded, fetching a very large list or hash (e.g., 500MB) at once can block the entire server.
Solution: Splitting data into pieces (sharding) or preferring SCAN commands.
Hot Keys
Some keys (such as a popular product page) receive significantly more demand than others.
Solution: Adding a local L1 cache layer for these keys (In-memory cache in front of Redis).
9. Modern Libraries and Tools
Some modern tools used to accelerate the development process include:
DragonflyDB: A Redis-compatible, multi-threaded next-generation in-memory data store.
Redisson: A library for Java that provides advanced distributed objects (Lock, AtomicLong, Map) via Redis.
Garrison: Middleware solutions that manage cache clearing and invalidation processes.
10. Conclusion: Which One to Choose?
If your application only needs simple key-value storage and will run under very high concurrency, Memcached stands out with its memory efficiency and multi-threaded structure. However, if you will be performing operations with complex data types, want the data to be persistent, and add real-time features (pub/sub, streams), Redis is the absolute leader.
In modern architectures, both can often be used as a hybrid: Redis for session management, Memcached for static HTML snippets or simple object caching. The important thing is to properly configure data consistency and cache invalidation policies according to the system’s needs.
Technical Note: In Redis Cluster configurations, network jitter during MIGRATE commands should be monitored, and the cluster-node-timeout value should be optimized based on traffic intensity. Using MessagePack or Protobuf instead of JSON for data serialization can reduce both CPU costs and network bandwidth usage by 30-50%.