We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
Migrations and Data Security: Schema Updates Without Data Loss in Production
In the software development lifecycle (SDLC), the evolution of an application inevitably requires changes to the database schema. However, performing a schema update in a production environment—on a live system containing millions of rows—is akin to “changing the engine of an airplane in flight.” An incorrect ALTER TABLE query can lead to table locking, service outages, or irreversible data loss.
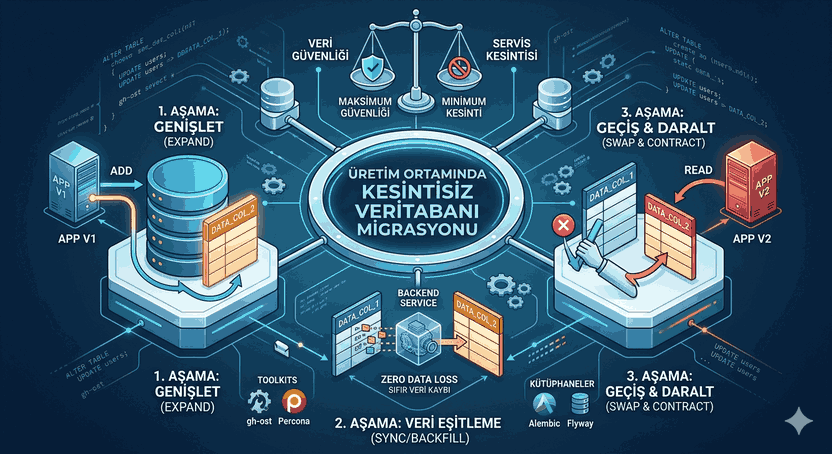
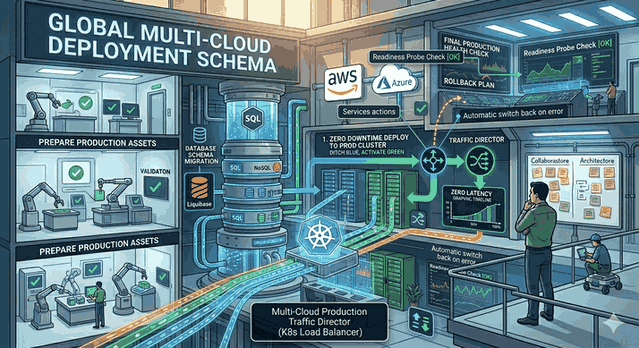
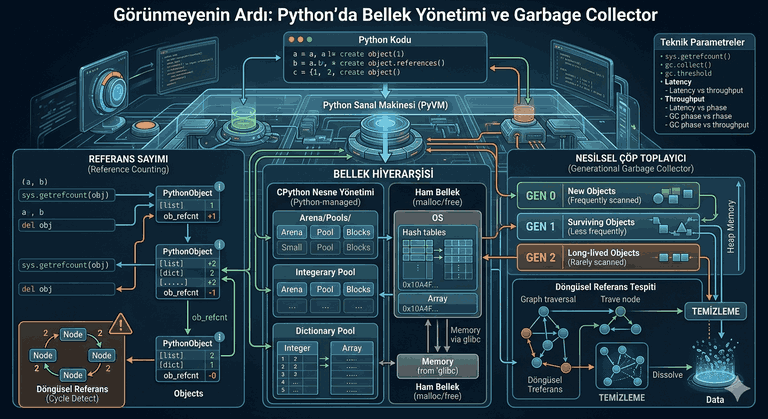
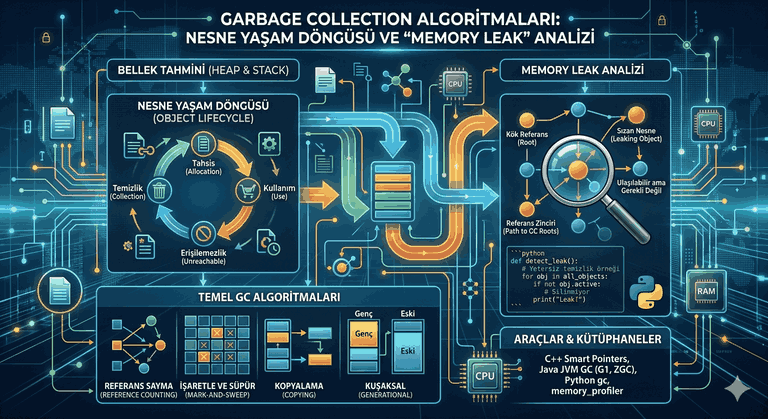
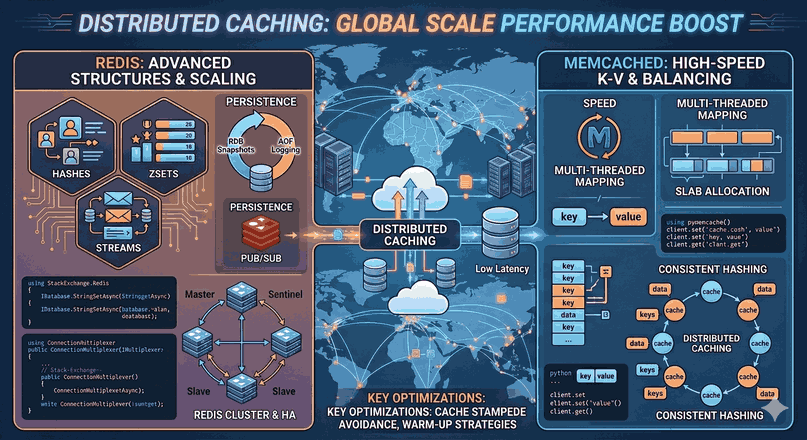
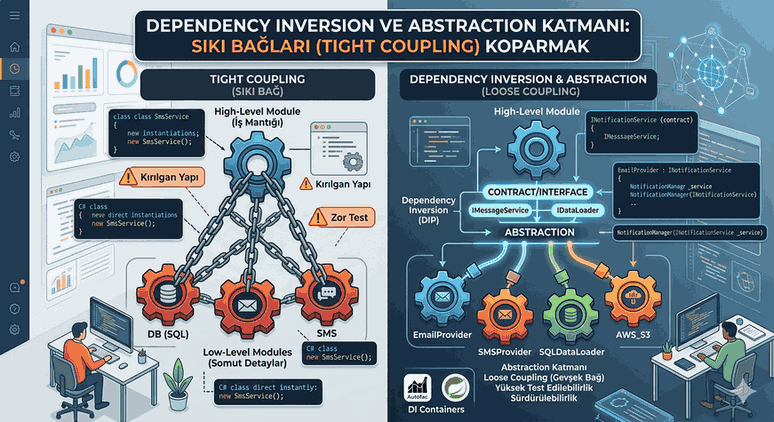
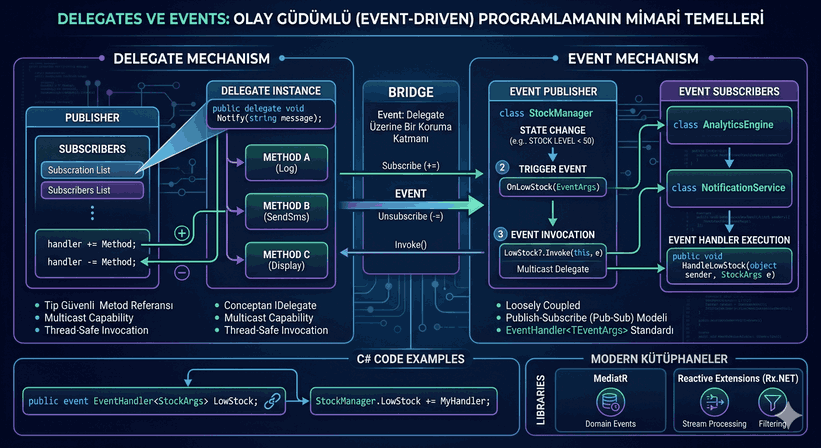
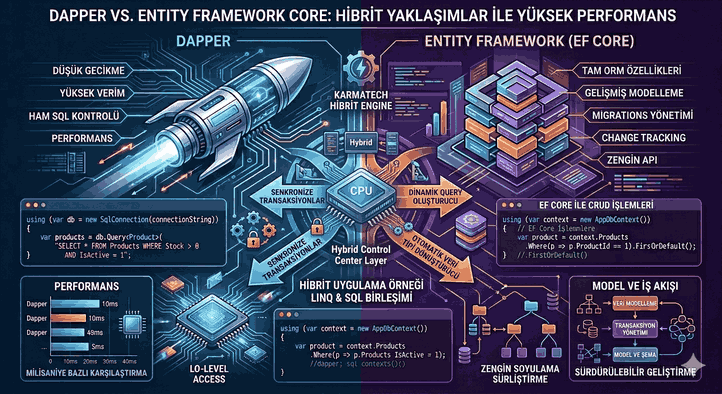
Figure 1: Migrations and Data Security: Schema Updates Without Data Loss in Production.
1. Fundamental Risks in Schema Changes and Locking Mechanisms
When a schema change is performed in relational databases (RDBMS), the database engine creates a Metadata Lock (MDL) on the relevant object to maintain data consistency.
DML (Data Manipulation Language):INSERT, UPDATE, and DELETE operations typically use row-level locks.
DDL (Data Definition Language): Operations like ALTER TABLE and CREATE INDEX may require table-level locks.
Especially in engines like MySQL (InnoDB), adding a column to a large table or changing a column type can lock the entire table for reading/writing. In a system under traffic, this causes requests to queue and eventually leads to a cascading failure.
2. Backward Compatibility: Two-Phase Deployment
The golden rule for preventing data loss and achieving zero downtime is to decouple code changes from database changes. Deleting or renaming a column should never be done in a single step.
Expand and Contract Pattern
This strategy ensures that the application can operate with both the old and new schema structures simultaneously.
Phase 1 (Expand): The new column is added. The application code is updated; it now writes data to both the old and new columns but only reads from the old one.
Phase 2 (Sync): A backfill script running in the background migrates the old data to the new column.
Phase 3 (Switch): The application code is updated; it now reads data from the new column.
Phase 4 (Contract): The old column is safely removed.
3. Online Schema Change Tools
For large-scale databases, auxiliary tools that do not lock the table should be used instead of standard SQL commands. These tools generally work based on the “Shadow Table” concept.
gh-ost (GitHub Online Schema Transformer): Processes changes via binary logs without using triggers. It minimizes the load on the database.
pt-online-schema-change (Percona Toolkit): Creates a copy of the target table, performs changes on the copy, and synchronizes live data via triggers. It performs an atomic swap of the tables once the process is complete.
4. Technical Implementation and Code Examples
To reduce manual intervention during migration processes, tools like Flyway or Liquibase should be used. Below are examples of secure migrations in Python (SQLAlchemy/Alembic) and Node.js (Knex.js) ecosystems.
Example: Secure Column Addition with Alembic (PostgreSQL)
Adding a NOT NULL constraint to a column in PostgreSQL requires a default value for existing rows, which is risky for large tables.
"""Adding a column and applying constraints incrementally"""from alembic import op
import sqlalchemy as sa
defupgrade():
# Step 1: Add the column as nullable (Fast operation) op.add_column('users', sa.Column('account_status', sa.String(20), nullable=True))
# Step 2: Update default values in the background (Batching)# This part is usually done at the application level or via small-chunk SQLs. op.execute("UPDATE users SET account_status = 'active' WHERE account_status IS NULL")
# Step 3: Add the NULL constraint later op.alter_column('users', 'account_status', nullable=False)
defdowngrade():
op.drop_column('users', 'account_status')
Example: Index Management with Knex.js
When creating an index in a production environment, the CONCURRENTLY keyword is vital.
// Non-blocking index creation for PostgreSQL
exports.up=function(knex) {
returnknex.raw('CREATE INDEX CONCURRENTLY idx_user_email ON users(email)');
};
exports.down=function(knex) {
returnknex.raw('DROP INDEX CONCURRENTLY idx_user_email');
};
Note: The use of CONCURRENTLY does not work within transaction blocks; therefore, the transaction settings of the migration tool must be configured accordingly.
5. Data Migration and Batching
In cases where not just the structure but the data itself changes (e.g., parsing a JSON field), attempting to update the entire table with a single UPDATE query can fill the transaction log and make the database unresponsive.
Ideal Approach: Process the data in small chunks.
-- Logic for secure data updates in a large table
DO$$DECLARErow_count INT;
BEGIN LOOP
UPDATE orders
SET status_code =1WHERE status_code ISNULLAND id IN (SELECT id FROM orders WHERE status_code ISNULLLIMIT5000);
GETDIAGNOSTICSrow_count=ROW_COUNT;
EXIT WHENrow_count=0;
COMMIT; -- Release locks by committing after each chunk
PERFORM pg_sleep(0.1); -- Let the database catch its breath
END LOOP;
END$$;
6. Blue-Green Deployment and the Database Layer
If Blue-Green deployment is used at the application layer, the database must be compatible with both versions.
Blue (Old Version): Works with schema v1.
Green (New Version): Works with schema v2.
If the migration upgrades the schema to v2 and an error occurs in the Green version, the application should not fail when reverting to the Blue version. Therefore, Breaking Changes should always be cleaned up in the next version (N+1).
7. Migration Security Checklist
Before pushing a migration to the production environment, the following technical criteria must be verified:
Lock Analysis: Does the ALTER TABLE operation lock the table? Has the duration been simulated in a test environment (with production data volume)?
Rollback Plan: Is the downgrade script ready? Is there a backup available if data was deleted?
Backup: Was a backup with Point-in-Time Recovery (PITR) support taken before the migration?
Dependencies: Are database triggers, views, or stored procedures breaking during the migration?
Disk Space: Some ALTER operations create a copy of the table. Is there sufficient disk space on the server (at least as much free space as the table size)?
8. Advanced Libraries and Toolkits
Popular tools used for migration management in modern microservice architectures:
Java/Kotlin: Flyway, Liquibase.
Go: Golang-migrate, SQL-migrate.
Node.js: TypeORM, Sequelize, Prisma.
Python: Alembic (built-in makemigrations for Django).
Ruby: Active Record Migrations.
Final Notes and Strategic Importance
Database migrations are not just pieces of code; they are critical operations that determine the continuity of the system. The “move fast and break things” philosophy does not apply to the database layer. Defensive programming principles must always be applied, the atomic structure of the data must be preserved, and migration tests (dry-run) should be integrated into automated test processes (CI/CD).
It should be remembered that while an error in the application code can be fixed in minutes, recovering corrupted or lost data can take hours or even days. Therefore, planning for the worst-case scenario is essential in migration strategies.