We use cookies and other tracking technologies to improve your browsing experience on our website, to show you personalized content and targeted ads, to analyze our website traffic, and to understand where our visitors are coming from.
⚠️
GDPR & Cookie Policy Notice
In accordance with data protection regulations; the use of mandatory cookies is required for the core functions of our website to operate, ensure data security, and perform analytics. If you reject the use of cookies, it is not possible to benefit from the services on our website due to technical limitations and data synchronization interruptions. You must consent to the use of cookies to access the content on our site.
The Layered Architecture and Algorithmic Depth of Machine Learning
The artificial intelligence and machine learning ecosystem is built upon a vertical hierarchy that extends from raw data to abstract inferences. This journey begins at the lowest level with hardware and machine language, and concludes at the highest level with philosophical deductions and high-level cognitive modeling. For an engineer, understanding the transition between these layers means not just writing code, but mastering the behavioral mechanics of the system.
Figure 1: The Layered Architecture and Algorithmic Depth of Machine Learning.
The Hierarchical Ladder from Data to Understanding
Information is inherently layered. While the lower layers represent concrete, measurable, and deterministic data (e.g., hormone levels in a biological process), the upper layers contain abstract concepts (like the philosophical definition of happiness) that emerge from processing this data. In machine learning, this hierarchy is the process of transitioning from low-level features to high-level representations.
In a technical context, proceeding to the coding phase without absorbing the mathematical models is akin to setting sail on the ocean without a compass. In debugging and model optimization processes, one must master the underlying calculus and linear algebra structures to understand why an algorithm fails.
The Role of Programming Languages and Memory Management
In the software world, languages are distinguished by their levels of abstraction. While languages like C++ offer high efficiency in terms of memory management (heap/stack control) and writing CPU-friendly code, the learning curve is steep. The reason Python dominates modern machine learning projects is the rich library ecosystem it offers.
Python conceals low-level complexity through “wrapper” libraries, allowing researchers to focus on algorithmic logic. For instance, while NumPy accelerates matrix calculations with vectorized operations, libraries like PyTorch and TensorFlow automate tensor operations and gradient calculations.
import numpy as np
# Matrix operations: The basis of linear algebradefoptimize_weights(X, y):
# Closed-form solution (Normal Equation): theta = (X^T * X)^-1 * X^T * y weights = np.linalg.inv(X.T @ X) @ X.T @ y
return weights
Supervised Learning and Function Convergence
Supervised Learning is the process of establishing a mapping $f(x) \rightarrow y$. Here, as the input dimension increases, the model’s capacity to capture complex relationships within the data also increases. Today’s massive language models (LLMs) are essentially performing a multi-dimensional “curve fitting” operation.
Two critical concepts emerge in this process: Interpolation and Extrapolation.
Interpolation: The model generating new predictions by filling in the gaps within the training data range. The “creativity” of artificial intelligence usually occurs in this safe zone between existing data points.
Extrapolation: Making predictions in regions outside the scope covered by the training data. It is statistically risky because the model is expected to generalize in a distribution it has not seen. The fundamental difference that distinguishes human intelligence from machines is the ability to perform accurate extrapolation starting from limited data.
Unsupervised Learning: The Hidden Geometry of Data
In scenarios where data is unlabeled, Unsupervised Learning comes into play. This approach analyzes the topological structure and clustering tendencies of the data. For example, manually labeling half a million images of cats and dogs is an operational nightmare. Unsupervised models separate data into their natural groups by analyzing feature vectors (color distribution, ear structure, size).
Techniques like K-Means or PCA (Principal Component Analysis) aim to preserve the most important information (variance) by reducing the dimensionality in the data.
from sklearn.cluster import KMeans
# Clustering data based on features without labelingmodel = KMeans(n_clusters=2)
clusters = model.fit_predict(image_features)
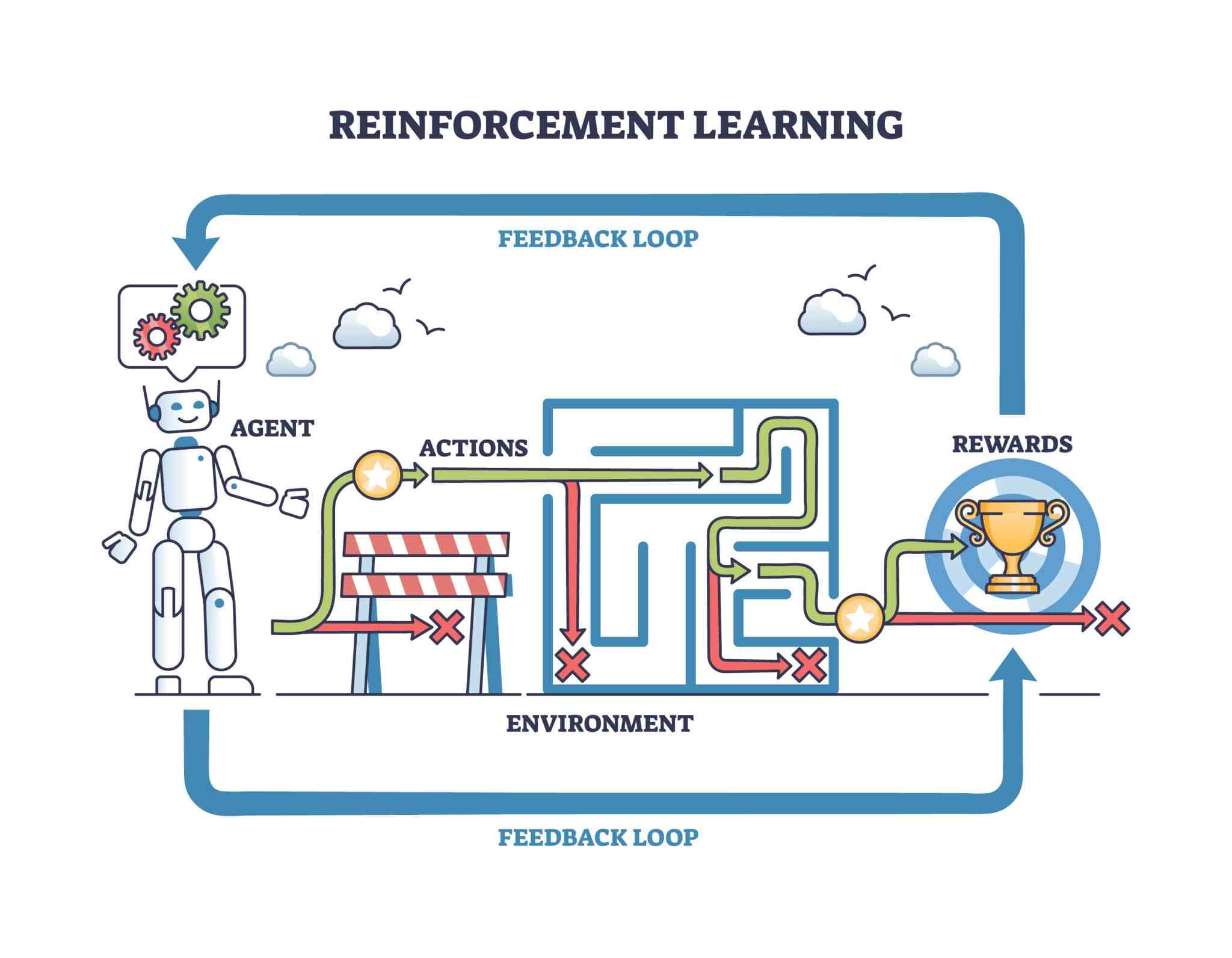
Reinforcement Learning (RL) is the process of an agent learning the strategy (policy) it must follow to collect the maximum reward in an environment. RL is unrivaled in delayed reward problems. In games like Chess or Go, the correctness of a move made is not apparent immediately, but rather at the end of the game.
The fundamental components of RL:
State: The agent’s current position or data.
Action: The moves the agent can perform.
Reward: The feedback received as a result of an action.
Policy: The mapping function from states to actions ($\pi$).
Figure 2: Reinforcement Learning.
Mathematically, RL is built upon Bellman equations. The value of a state ($V(s)$) is the sum of the immediate reward to be received from that state and the expected future rewards.
Note: The “Exploration vs. Exploitation” balance is critical in RL algorithms. The agent must choose between following the path it knows (exploitation) and exploring new and potentially more profitable paths (exploration).
Convex Optimization and Stability
In machine learning, training models is essentially an optimization problem. We try to minimize a cost function (loss function). If the function is Convex, local minima are equal to the global minimum; this guarantees that the algorithm will stably reach the best result. In more complex fields like RL, functions are generally not convex, which is why hyperparameter management and architectural design are vital.
Conclusion and Future Projection
Machine learning is a field inspired by nature but shaped by mathematical discipline. From the neurobiological origins of neural networks to the attention mechanisms of modern Transformer architectures, data gains meaning layer by layer. Future systems will be “intelligent” structures capable of making logical inferences not just by processing existing data, but in areas where no data exists (extrapolation).
To succeed in this journey, one must never forget how the low-level mathematical engine works while taking advantage of the conveniences offered by high-level libraries.
Technical Notes:
Model Complexity: Using unnecessarily high-dimensional input increases the risk of “Overfitting.”
Data Quality: The “Garbage in, garbage out” principle always applies; cleaning and normalizing data is more critical than algorithm selection.
Hardware Acceleration: Using GPU (CUDA) or TPU instead of CPU for large datasets can shorten training times by thousands of times.