Size daha iyi hizmet sunabilmek için çerezleri kullanıyoruz.
Web sitemizde gezinme deneyiminizi geliştirmek, size kişiselleştirilmiş içerik ve hedefli reklamlar göstermek, web sitesi trafiğimizi analiz etmek ve ziyaretçilerimizin nereden geldiğini anlamak için çerezleri ve diğer izleme teknolojilerini kullanıyoruz.
⚠️
KVKK ve Çerez Politikası Bilgilendirmesi
6698 sayılı Kişisel Verilerin Korunması Kanunu (KVKK) ve Aydınlatma Yükümlülüğü kapsamında; web sitemizin temel fonksiyonlarının çalışabilmesi, veri güvenliğinin sağlanması ve performans analizi yapılabilmesi için zorunlu çerezlerin kullanımı gerekmektedir. Çerez kullanımını reddetmeniz halinde, teknik imkansızlıklar ve veri senkronizasyonu kesintileri nedeniyle web sitemizdeki hizmetlerden yararlanmanız mümkün olmamaktadır. Sitemizdeki içeriklere erişebilmek için çerez kullanımını onaylamanız gerekmektedir.
Makine Öğrenmesinin Katmanlı Mimarisi ve Algoritmik Derinliği
Yapay zeka ve makine öğrenmesi ekosistemi, ham veriden soyut çıkarımlara uzanan dikey bir hiyerarşi üzerine kuruludur. Bu yolculuk, en alt katmanda donanım ve makine diliyle başlarken, en üst katmanda felsefi çıkarımlar ve yüksek seviyeli bilişsel modellemelerle son bulur. Bir mühendis için bu katmanlar arasındaki geçişi anlamak, sadece kod yazmak değil, sistemin davranışsal mekaniğine hükmetmek anlamına gelir.
Şekil 1: Makine Öğrenmesinin Katmanlı Mimarisi ve Algoritmik Derinliği.
Veriden Anlama Giden Hiyerarşik Merdiven
Bilgi, doğası gereği katmanlıdır. Alt katmanlar somut, ölçülebilir ve deterministik verileri (örneğin biyolojik bir süreçteki hormon seviyeleri) temsil ederken; üst katmanlar bu verilerin işlenmesiyle ortaya çıkan soyut kavramları (mutluluğun felsefi tanımı gibi) barındırır. Makine öğrenmesinde bu hiyerarşi, düşük seviyeli özelliklerden (feature) yüksek seviyeli temsillere (representation) geçiş sürecidir.
Teknik bir bağlamda, matematiksel modelleri özümsemeden kodlama aşamasına geçmek, pusulasız okyanusa açılmaya benzer. Hata ayıklama (debugging) ve model optimizasyonu süreçlerinde, algoritmanın neden başarısız olduğunu anlamak için alttaki kalkülüs ve lineer cebir yapılarına hakim olmak gerekir.
Programlama Dillerinin Rolü ve Bellek Yönetimi
Yazılım dünyasında diller, soyutlama seviyelerine göre ayrılır. C++ gibi diller, bellek yönetimi (heap/stack kontrolü) ve CPU dostu kod yazımı açısından yüksek verimlilik sunsa da öğrenme eğrisi diktir. Modern makine öğrenmesi projelerinde Python’un domine edici olmasının sebebi, sunduğu zengin kütüphane ekosistemidir.
Python, alt seviye karmaşıklığı “wrapper” kütüphaneler aracılığıyla gizleyerek araştırmacıların algoritmik mantığa odaklanmasını sağlar. Örneğin, NumPy vektörize işlemlerle matris hesaplamalarını hızlandırırken, PyTorch ve TensorFlow gibi kütüphaneler tensör operasyonlarını ve gradyan hesaplamalarını otomatikleştirir.
import numpy as np
# Matris operasyonları: Lineer cebir temelidefoptimize_weights(X, y):
# Kapalı form çözümü (Normal Denklem): theta = (X^T * X)^-1 * X^T * y weights = np.linalg.inv(X.T @ X) @ X.T @ y
return weights
Denetimli Öğrenme ve Fonksiyon Yakınsama
Denetimli Öğrenme (Supervised Learning), bir $f(x) \rightarrow y$ eşlemesi kurma sürecidir. Burada girdi (input) boyutu arttıkça, modelin veri içindeki karmaşık ilişkileri yakalama kapasitesi de artar. Günümüzün devasa dil modelleri (LLM), aslında çok boyutlu bir “curve fitting” (eğri uydurma) operasyonu yürütür.
Bu süreçte iki kritik kavram karşımıza çıkar: Interpolation ve Extrapolation.
Interpolation: Modelin, eğitim verisi aralığı içindeki boşlukları doldurarak yeni tahminler üretmesidir. Yapay zekanın “yaratıcılığı” genellikle mevcut veri noktaları arasındaki bu güvenli bölgede gerçekleşir.
Extrapolation: Eğitim verisinin kapsamadığı dış bölgelerde tahminde bulunmaktır. İstatistiksel olarak risklidir çünkü modelin görmediği bir dağılımda genelleme yapması beklenir. İnsan zekasını makinelerden ayıran temel fark, kısıtlı veriden yola çıkarak doğru ekstrapolasyon yapabilme yeteneğidir.
Denetimsiz Öğrenme: Verinin Gizli Geometrisi
Verinin etiketlenmediği (unlabeled) senaryolarda, Denetimsiz Öğrenme (Unsupervised Learning) devreye girer. Bu yaklaşım, verinin topolojik yapısını ve kümelenme eğilimlerini analiz eder. Örneğin, yarım milyon kedi ve köpek görselini manuel etiketlemek (labeling) operasyonel bir kabustur. Denetimsiz modeller, öznitelik vektörlerini (renk dağılımı, kulak yapısı, boyut) analiz ederek veriyi doğal gruplarına ayırır.
K-Means veya PCA (Temel Bileşen Analizi) gibi teknikler, verideki boyutluluğu azaltarak en önemli bilgiyi (variance) korumayı hedefler.
from sklearn.cluster import KMeans
# Veriyi özelliklerine göre etiketlemeden kümelememodel = KMeans(n_clusters=2)
clusters = model.fit_predict(image_features)
Pekiştirmeli Öğrenme: Dinamik Karar Mekanizmaları
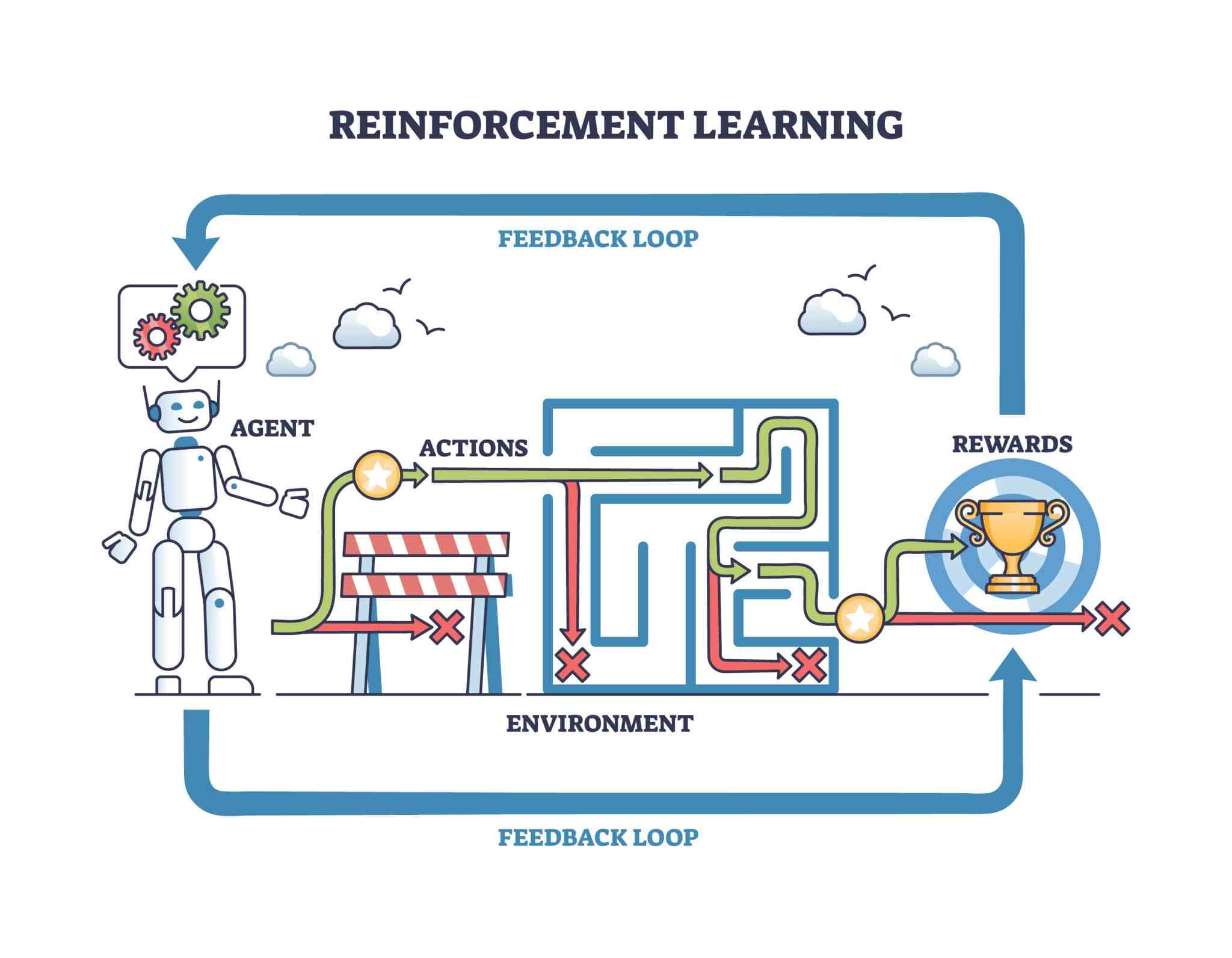
Pekiştirmeli Öğrenme (Reinforcement Learning - RL), bir ajanın (agent) bir ortamda (environment) maksimum ödülü (reward) toplamak için izlemesi gereken stratejiyi (policy) öğrenmesidir. RL, gecikmeli ödül problemlerinde rakipsizdir. Satranç veya Go gibi oyunlarda, yapılan bir hamlenin doğruluğu hemen değil, oyunun sonunda belli olur.
RL’nin temel bileşenleri:
State (Durum): Ajanın o andaki konumu veya verisi.
Reward (Ödül): Eylem sonucunda alınan geri bildirim.
Policy (Politika): Durumlardan eylemlere giden eşleme fonksiyonu ($\pi$).
Şekil 2: Pekiştirmeli Öğrenme.
Matematiksel olarak RL, Bellman denklemleri üzerine inşa edilir. Bir durumun değeri ($V(s)$), o durumdan alınacak anlık ödül ve gelecekteki beklenen ödüllerin toplamıdır.
Not: RL algoritmalarında “Exploration vs. Exploitation” (Keşif ve Faydalanma) dengesi kritiktir. Ajan, bildiği yoldan gitmek (exploitation) ile yeni ve potansiyel olarak daha kârlı yollar keşfetmek (exploration) arasında bir seçim yapmalıdır.
Konveks Optimizasyon ve Kararlılık
Makine öğrenmesinde modellerin eğitilmesi, aslında bir optimizasyon problemidir. Bir maliyet fonksiyonunu (loss function) minimize etmeye çalışırız. Eğer fonksiyon Konveks (Dışbükey) ise, yerel minimumlar küresel minimuma eşittir; bu da algoritmanın kararlı bir şekilde en iyi sonuca ulaşacağını garanti eder. RL gibi daha karmaşık alanlarda fonksiyonlar genellikle konveks değildir, bu yüzden hiperparametre yönetimi ve mimari tasarım hayati önem taşır.
Sonuç ve Gelecek Projeksiyonu
Makine öğrenmesi, doğadan ilham alan ancak matematiksel disiplinle şekillenen bir alandır. Sinir ağlarının nörobiyolojik kökenlerinden, modern Transformer mimarilerinin dikkat (attention) mekanizmalarına kadar her adımda veri, katman katman anlam kazanır. Geleceğin sistemleri, sadece mevcut veriyi işleyen değil, veri olmayan alanlarda (extrapolation) mantıksal çıkarımlar yapabilen “akıllı” yapılar olacaktır.
Bu yolculukta başarılı olmak için, üst seviye kütüphanelerin sunduğu kolaylıklardan faydalanırken, alt seviyedeki matematiksel motorun nasıl çalıştığını asla unutmamak gerekir.
Teknik Notlar:
Model Karmaşıklığı: Gereksiz yüksek boyutlu girdi kullanımı “Overfitting” (aşırı öğrenme) riskini artırır.
Veri Kalitesi: “Garbage in, garbage out” (Çöp girerse çöp çıkar) prensibi her zaman geçerlidir; verinin temizlenmesi ve normalizasyonu, algoritma seçiminden daha kritiktir.
Donanım Hızlandırma: Büyük veri setlerinde CPU yerine GPU (CUDA) veya TPU kullanımı, eğitim sürelerini binlerce kat kısaltabilir.