Size daha iyi hizmet sunabilmek için çerezleri kullanıyoruz.
Web sitemizde gezinme deneyiminizi geliştirmek, size kişiselleştirilmiş içerik ve hedefli reklamlar göstermek, web sitesi trafiğimizi analiz etmek ve ziyaretçilerimizin nereden geldiğini anlamak için çerezleri ve diğer izleme teknolojilerini kullanıyoruz.
⚠️
KVKK ve Çerez Politikası Bilgilendirmesi
6698 sayılı Kişisel Verilerin Korunması Kanunu (KVKK) ve Aydınlatma Yükümlülüğü kapsamında; web sitemizin temel fonksiyonlarının çalışabilmesi, veri güvenliğinin sağlanması ve performans analizi yapılabilmesi için zorunlu çerezlerin kullanımı gerekmektedir. Çerez kullanımını reddetmeniz halinde, teknik imkansızlıklar ve veri senkronizasyonu kesintileri nedeniyle web sitemizdeki hizmetlerden yararlanmanız mümkün olmamaktadır. Sitemizdeki içeriklere erişebilmek için çerez kullanımını onaylamanız gerekmektedir.
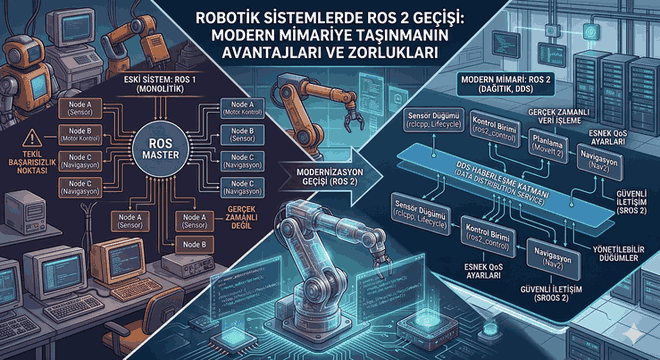
Otonom Robotik Sistemlerde Derin Öğrenme Temelli Nesne Algılama ve Manipülasyon Teknikleri
Modern robotik sistemlerin temel taşını oluşturan nesne tanıma ve kavrama (grasping) süreçleri, geleneksel bilgisayarlı görü yöntemlerinden sıyrılarak tamamen derin öğrenme (Deep Learning) mimarileri üzerine inşa edilmektedir. Bir robotun fiziksel dünyayla etkileşime girmesi, sadece nesnenin koordinatlarını bilmesini değil, aynı zamanda nesnenin geometrik yapısını, materyal özelliklerini ve yaklaşım açılarını analiz etmesini gerektirir.
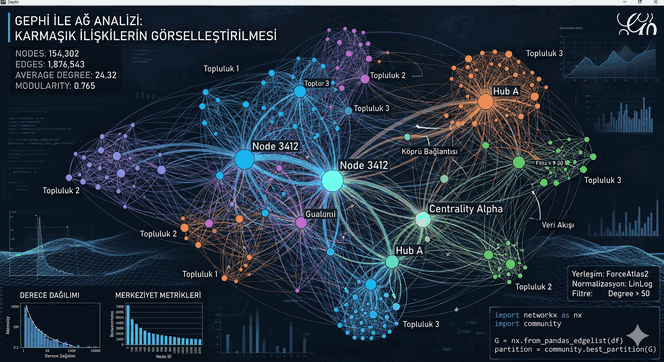
Şekil 1: Otonom Robotik Sistemlerde Derin Öğrenme Temelli Nesne Algılama ve Manipülasyon Teknikleri.
Derin Öğrenme Tabanlı Nesne Algılama Mimarileri
Robotik sistemlerde gerçek zamanlı çıkarım (inference) hayati önem taşır. Bu noktada iki temel yaklaşım öne çıkmaktadır: Tek aşamalı (one-stage) dedektörler ve iki aşamalı (two-stage) dedektörler.
YOLO (You Only Look Once) Serisi: Robotik kollarda en çok tercih edilen mimaridir. Görüntüyü bir ızgaraya (grid) bölerek her hücre için nesne olasılıklarını ve sınırlayıcı kutu (bounding box) koordinatlarını aynı anda tahmin eder. YOLOv8 ve üzeri sürümler, özellikle düşük gecikme süresiyle (latency) mobil robot platformları için optimize edilmiştir.
Faster R-CNN: Daha yüksek doğruluk gerektiren hassas montaj görevlerinde kullanılır. Bölge Öneri Ağı (RPN) sayesinde nesne adaylarını belirler ve ardından sınıflandırma yapar.
Örnek Uygulama: PyTorch ile Basit Bir Nesne Algılama Arayüzü
Aşağıdaki kod bloğu, bir robotik vizyon sisteminde önceden eğitilmiş bir modeli yükleyerek nesne tespiti yapmanın temel mantığını göstermektedir:
import torch
import cv2
# Model yükleme (YOLOv5 örneği)model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
defdetect_objects(frame):
# Görüntü üzerinde çıkarım yapma results = model(frame)
# Koordinatları ve sınıfları alma predictions = results.pandas().xyxy[0]
for index, row in predictions.iterrows():
x1, y1, x2, y2 = int(row['xmin']), int(row['ymin']), int(row['xmax']), int(row['ymax'])
label = row['name']
conf = row['confidence']
# Robotik kontrol için merkez noktası hesaplama center_x = (x1 + x2) //2 center_y = (y1 + y2) //2 cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, f"{label}{conf:.2f}", (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
return frame, predictions
# Kamera akışı üzerinden testcap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
ifnot ret: break output_frame, _ = detect_objects(frame)
cv2.imshow('Robot Vision', output_frame)
if cv2.waitKey(1) &0xFF== ord('q'): breakcap.release()
cv2.destroyAllWindows()
Nesneyi tanımak, onu başarılı bir şekilde kavramak için yeterli değildir. Robotun, nesneye hangi açıdan yaklaşacağını (pose estimation) ve tutucunun (gripper) parmaklarını nereye yerleştireceğini hesaplaması gerekir.
GPD (Grasp Pose Detection) ve PointNet++
3D veri işleme, robotik manipülasyonda standart hale gelmiştir. RGB-D kameralardan gelen nokta bulutu (Point Cloud) verileri, PointNet++ veya PointCNN gibi mimarilerle işlenerek nesnenin yüzey normalleri çıkarılır. Kavrama noktası belirleme algoritmaları, bu veriler üzerinde binlerce aday kavrama açısı oluşturur ve her birine bir “başarı skoru” atar.
Veri Setleri ve Kütüphaneler
Robotik vizyon geliştirmelerinde kullanılan başlıca kaynaklar şunlardır:
OpenCV: Görüntü ön işleme ve filtreleme.
PCL (Point Cloud Library): 3D veri işleme için endüstri standardı.
ROS 2 (Robot Operating System): Algoritmaların donanım ile iletişimini sağlayan ara katman yazılımı.
MoveIt: Hareket planlama (path planning) için kullanılan gelişmiş bir framework.
Derin Takviyeli Öğrenme (Deep Reinforcement Learning) ile Kavrama
Klasik algoritmaların başarısız olduğu karmaşık senaryolarda (örneğin üst üste binmiş düzensiz nesneler), Deep RL devreye girer. Robot, simülasyon ortamında (Nvidia Isaac Gym veya PyBullet) binlerce kez deneme yanılma yaparak en doğru kavrama stratejisini öğrenir.
Q-Learning Mimarisi: Robotun her bir hareketi (aksiyon), çevreden aldığı ödül (başarılı kavrama) ile değerlendirilir. Sinir ağı, $Q(s, a)$ değerini yani belirli bir durumda ($s$) yapılan hareketin ($a$) gelecekteki toplam ödül beklentisini maksimize etmeye çalışır.
$$Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma \max_{a'} Q(s', a') - Q(s, a)]$$
Bu denklemde $\alpha$ öğrenme oranını, $\gamma$ ise gelecek ödüllerin önemini (discount factor) temsil eder.
Segmentasyon ve Maskeleme: Mask R-CNN ve SAM
Sadece sınırlayıcı kutu kullanmak, nesnenin tam sınırlarını belirlemediği için hassas kavrama operasyonlarında hata payını artırır. İlgi Alanı Segmentasyonu (Instance Segmentation) teknikleri, nesneyi piksel düzeyinde maskeler. Meta tarafından geliştirilen SAM (Segment Anything Model), sıfır-örnekli (zero-shot) öğrenme yeteneği ile robotik vizyonda devrim yaratmıştır. Robot, daha önce hiç görmediği bir nesnenin formunu anında kavrayabilir.
Donanım ve Yazılım Entegrasyonu: Jetson ve TensorRT
Yapay zeka modellerinin robot üzerinde koşturulması için yüksek hesaplama gücü gerekir. NVIDIA Jetson serisi gibi gömülü sistemler, CUDA çekirdekleri sayesinde derin öğrenme modellerini optimize eder. TensorRT kütüphanesi kullanılarak, PyTorch veya TensorFlow modelleri FP16 veya INT8 hassasiyetine indirilerek çıkarım hızı 10 kata kadar artırılabilir.
Teknik Not: Robotik uygulamalarda modelin doğruluğu kadar, deterministik çalışması da önemlidir. Gecikme süresindeki (jitter) dalgalanmalar, kontrol döngüsünde (control loop) kararsızlıklara ve mekanik hasarlara yol açabilir.
Gelecek Projeksiyonu: Uçtan Uca (End-to-End) Öğrenme
Gelecekteki robotik sistemler, nesne tanıma ve hareket planlamayı ayrı modüller olarak değil, tek bir sinir ağı üzerinden yürütecektir. Vision-Language-Action (VLA) modelleri sayesinde robot, “Masadaki kırmızı kupayı al ve kahve makinesinin yanına koy” gibi doğal dil komutlarını doğrudan görsel verilerle eşleştirerek motor tork değerlerine dönüştürebilecektir.
Bu teknolojik dönüşüm, sadece fabrikalarda değil, ev tipi asistan robotlarda ve arama-kurtarma operasyonlarında kullanılan otonom sistemlerde de yeni bir dönemi başlatmaktadır. Derin öğrenmenin esnekliği, robotların dinamik ve öngörülemeyen ortamlarda insan benzeri adaptasyon yeteneği kazanmasını sağlamaktadır.